Общий обзор и классификация систем мониторинга (Вячеслав Милованов, Paessler)
Когда используемый сценарий мониторинга, построенная инфраструктура перестают быть адекватной, становятся слишком сложными, проявляются серьезные пробелы в знаниях о мониторинге. Все это осложняется отсутствием документов. При таком беглом обзоре очевидно: тема сложная, а решения бесчисленны.
Практически каждое решение обещает идеальный мониторинг, предлагает самые разные концепции, самый разные методы. Давайте попробуем сегодня с вами вместе определить основные виды мониторинга, понять место продуктов на рынке, ну и вместе прийти к пониманию, какой из них выбрать.
Что такое IT-мониторинг?
Основную функцию IT-мониторинга можно разбить на четыре задачи:
- сбор данных о доступности и эффективности IT-компонентов
- сохранение принятых данных
- оповещения и предупреждения на основе полученной информации и установленных пороговых значений
- визуализация результатов в виде обзоров, отчетов, дашбордов и т. п.
Нельзя отрицать тот факт, что среди IT-мониторинга существует множество расширенных и углубленных задач, например выявление первопричин, анализ или распознавание тенденций (сейчас часто применяется термин “искусственный интеллект”, сложные алгоритмы) и следующие за этим прогнозы на основе анализа. Естественно аспекты безопасности, мониторинг работы сетей, брандмауэров, распознавание возможных попыток вторжения и т. д.
Суммируя, мониторинг — это простой процесс: сбор, хранение, публикация данных + оповещения на основе установленных пороговых значений. Существует множество инструментов, входящих в понятие мониторинг, и все они обеспечивают тот или иной ряд функций, помимо чистого мониторинга.
Мы с вами имеем счастье жить в сомнительные 20-е годы 21 века. Что на сегодняшний день представляет из себя мониторинг? Притча во языцех — облака и связанные с ними приложения. Они уже приобрели серьезное значение и продолжают приобретать.
Пандемия, COVID-19 и вызванные изменения в рабочей ситуации (я говорю о массовом переходе “на удаленку”, на совершенно новые форматы работы, и не только в IT) не изменили ситуацию в корне, но сдвиг в сторону облачных технологий получил серьезный толчок. Однако нельзя говорить о замене одной технологии другой, мы говорим о дополнении, поскольку подавляющее число IT (системная часть, базы данных и т.д.) осуществляются локально в компании, собственно в ЦОДе, новые нормы становятся дополнением, это комбинация. Несчастные администраторы и IT Ops несут равную ответственность как за локальное IT, так и за хранилища в частных или общественных облаках, а это означает, что такому администратору, которому довелось работать в гибридной среде, нужно иметь контроль в равной степени над составляющими решения.
Провайдеры, которые обеспечивают нам доступ к облакам и приложениям, могут полагаться на облачные решения для мониторинга. Локальные решения, в свою очередь, по-прежнему используют весь диапазон имеющихся решений, как коммерческих, так и нет. Все это в комбинации приводит к ещё более серьезной дефрагментации и без того запутанной ситуации на рынке. Существуют специализированные инструменты для мониторинга трафика, баз данных, и ещё там много чего можно мониторить, для каждой практически сферы деятельности в IT есть свой инструмент.
Чем больше растет значимость облачных приложений, тем больше дискуссий и обсуждений вокруг этой темы. В народе это называют “хайп”. В центре внимания у облачных провайдеров по-прежнему находятся пользователи. Удовлетворенные пользователи — главный объект, поэтому провайдеры мониторят скорость передачи данных, производительность облачных приложений на основе конкретных протоколов (например, flow-протоколы). Мониторинг на основе таких протоколов нацелен в основном на команды DevOps, которые отвечают как за свои приложения, так и за разработку и эксплуатацию. Для этой аудитории такие специализированные облачные мониторинговые решения обеспечивают достаточную степень детализации, углубленный анализ и т.д.
Но для всех остальных, а их большинство, требуется охват более широкий. Аспекты инфраструктуры, аспекты системной части — они остаются за рамками.
Подводя итоги, скажем,
- что гибридная форма — это новая норма
- пандемия увеличила значение облачных приложений
- рынок мониторинга отреагировал на все это еще более узко специализированными инструментами, которые не предлагают централизованного обзора
- а потребность в таком центральном контроле сохраняется и даже растет.

Решения для мониторинга можно разделить на три группы: узкоспециализированные, универсальные решения и “пакеты” (suits). Чем крупнее компания, чем глубже IT-среда, тем больше потребность в таких специализированных решениях. DevOps требуют детальной информации о приложениях, SecOps нуждаются в глубоком понимании аспектов сетевого трафика, связанных с безопасностью (помимо классических инструментов типа фаервола, сканера и антивируса), NetOps полагаются на глубокий анализ производительности сети.
В области анализа сети работают такие решения как Scrutinizer от Plixer, Flowmon или Kentik, которые даже иногда выходят за узкие рамки своего задуманного первоначального применения. Например, Flowmon, с которым мы успешно сотрудничаем, утверждает, что они в равной степени обслуживают и SecOps, и NetOps. Тем не менее, он остается решением для специалистов, которые не предлагают общего обзора всего IT в целом (и не претендуют на это).
Технически большинство специализированных инструментов основываются на очень-очень конкретном, очень небольшом наборе методов, методик и протоколов. При мониторинге сетей и приложений это часто потоковый или пакетный сниффинг. В области безопасности это может быть тоже потоковый/пакетный сниффинг, только уже с использованием глубокой проверки, распаковки пакетов: открыли, посмотрели внутрь, куда, откуда шло, а также мониторинг журнала событий.
Все инструменты обычно обеспечивают высокую производительность, в этом плюс специализированных решений, они предлагают серьезный анализ полученной информации, опираясь на искусственный интеллект или, как минимум, сложный алгоритм.
С другой стороны, работа с такими специализированными инструментами требует определенного навыка, то есть нельзя взять его (как бы оно ни было пестро и доступно сконфигурировано) и поставить, чтобы начать с этим работать и получать адекватную информацию, с которой можно работать. Нужно ноу-хау, нужно понимание того, что ты делаешь. Сам по себе изящный японский синтезатор не сделает вас музыкантом.
Если пользователю, администратору требуется более обширный обзор, понимание, что там происходит у меня, тут специализированные решения очень быстро достигают предела — этого они предложить не могут.
Подводя итоги, специализированные решения дают глубокие знания для экспертов, но и требуют соответствующую квалификацию, не дают широкого обзора, но никак не могут заменить универсальные решения в компании.

Каждая компания управляет массивными IT-средами локально, и это не изменится в ближайшем будущем. Есть некие предприятия, которые ни за что не пойдут в облака, и я даже не об оборонке, это медицина, поставщики электроэнергии, водоканалы и т.д. Никогда не уйдут в облака, они будут держать в подвале сервера и будут с ними работать. Чтобы получить централизованный обзор всех областей более-менее сложного ландшафта, необходимо решение для мониторинга, охватывающее максимально широкий диапазон. Эти решения не могут предложить такую детальную и глубокую информацию, как специализированные решения. Они просто не смогут работать из-за своей сложности, и выйдут за рамки любого бюджета: его будет невозможно ни купить, ни содержать.
Такие решения мы называем универсальными. Тут следует упомянуть много раз отпетый протокол SMNP, его хоронили много раз, а он живее всех живых. На его основе только и можно широко мониторить. Еще одна причина, по которой SMNP так прочно зацепился — IT-ландшафты не меняются сразу на 100%. Нет такого, что все снесли под корень в ЦОДе и заменили на новое. Они, как правило, обрастают новыми решениями и сосуществуют со старыми. Поэтому с одной стороны SMNP, с другой — современная такая система универсального мониторинга (которая должна еще работать через API, чтобы сотрудничать с современным ПО).
Кроме того, как мы считаем, современная универсальная система обязана выходить за стандартные рамки и поддерживать протоколы, которые до сегодняшнего дня считались “экзотикой”, например, MQTT или OPC UA для промышленных решений, MODBUS для автоматизации зданий и умных домов, другие протоколы из мира Интернета вещей.
И отдельно сделаю акцент — это мониторинг медицинских информационных систем — МИС. Мало кто сейчас занимается этим на рынке, но это приобретает все большее значение: средняя европейская клиника — минимум 100 серверов. Это сложное хозяйство, и его нужно мониторить. Содержать, опять же, и там несколько систем: здесь у тебя классическое IT, здесь медицина своим каким-то инструментом мониторится — это тоже очень сложно и приводит к тому же результату. Большой зоопарк — много ненужной работы. Естественно, все это дополняется достаточно легкой и увлекательной системой оповещений. Это достаточно верхнеуровневая история: случилась проблема — алерт. Никаких детальных анализов, никаких сложностей.
Такой вот централизованный обзор дает возможность погружаться в систему мониторинга не только тем, кто непосредственно с этим связан (администраторам, системщикам), но и руководщие слои вступают в дело. Универсалы дают возможность визуализировать полученные метрики таким образом, чтобы это было понятно и управленцам. Не нужно проходить 8 страниц по репорту и показывать, в чем там дело.
Итог: универсальные решения предлагают широкий обзор взамен глубокого анализа. Охватывают многие области IT-мониторинга; достаточно для мониторинга небольших фирм; сосредоточено на мониторинге как таковом, без углубленного анализа; способно, в силу охвата широкого диапазона, обнаружить корреляции между вещами, которые бы из разных инструментов не коррелировались (или только при помощи серьезных затрат).

Еще один класс мониторинговых инструментов — пакеты (или suit’ы). Некоторые производители, например, SolarWinds, предлагает комплексные пакеты, состоящие из отдельных решений. У кого-то так сложилось исторически — докупались фирмы; кто-то, может быть, намеренно так действует, чтобы продавать модульные системы. В основном, это разрозненные специализированные инструменты для мониторинга, также другие решения, которые берут на себя функцию всего, чего угодно: инвентаризация, распределение софта, управление API-адресами. Кроме того, такие производители предлагают своего рода центральную приборную панель, которая, как минимум, пытается объединить инструменты этого производителя в единый обзор.
Однако, на самом деле, это не значит, что эти решения по-настоящему интегрированы друг с другом. Часто даже существуют очень серьезные конфликты между отдельными модулями, бывает, что одна составляющая пакета имеет свой собственный формат данных, API не срастаются между собой. В общем, это тоже достаточно сложно.
Тем не менее, такие комплексы интересны с коммерческой точки зрения. Это может быть привлекательная цена, приобретение всего этого комплекса из одного источника, лицензирование и обращение за поддержкой упрощаются и т.д. Главное преимущество — один поставщик, один инвойс, один контакт для поддержки ПО или оборудования. Ну и вот в качестве минуса — отсутствие реальной интеграции между отдельными инструментами, и еще один важный для тех, кто считает деньги, в совокупности это может быть дорого.

Теперь, когда мы прошлись по классификациям, давайте ответим на вопрос: “Как смотрят на рынок мониторинга эксперты, которые зарабатывают себе на хлеб, анализируя рынок?”.
Мы говорим о компании Gartner, опираемся на них очень часто. Мы с вами поняли, что рынок мониторинга — очень сложная штука, посмотрим, что говорят те, кто этим занимается 7 дней в неделю. Есть журналисты, которые этим занимаются, есть рейтинги, но возьмем в качестве примера компанию Gartner. Там порядка 2000 сидят, анализируют мониторинговый рынок. Gartner был известен своим магическим квадратом, если кто-то занимался этим — знает, он отжил свое, и в последние два-три года появилось очень интересное новое решение — портал, который называется Peer Insights. Из этих инсайтов по меньшей мере четыре посвящены ключевым областям мониторинга: мониторинг производительности приложений, инструменты для мониторинга ИТ-инфраструктуры, мониторинг и диагностика производительности сети и мониторинг объединенных (унифицированных) коммуникаций.
Ещё другие категории мониторинга, помимо предложенного Gartner, это вендорский инструментарий (Cisco, NetApp, VMware) и различные софты для анализа банков данных, интернет-страниц, СХД и т.д.
Мы же возьмем с вами мониторинг и диагностику производительности сети, это самая длинная, самая большая категория с массой номинантов. Вот первая десятка: если грубо проанализировать этот список, то SolarWinds и MachineEngine — это два классических поставщика комплектов оборудования (у каждого по два инструмента).
PRTG Network Monitor, продукт компании Paessler, несмотря на свое название, является универсальным решением. Мы на втором месте после SolarWinds, и поддерживаем мы массу протоколов. Подробнее об этом позже. Мы занимаемся мониторингом IT-инфраструктуры в целом, поэтому в другом рейтинге Gartner’а, посвященном таким решениям, мы занимаем первое место по популярности.
Другие участники рейтинга продуктов для сети — ExtraHop и Kentik — предлагают классический мониторинг на основе NetFlow с удобным интерфейсом и фишками по безопасности. CatchPoint, например, концентрируется на мониторинге endpoint’ов.
Каждое решение более-менее универсально, полагается на свой набор протоколов. В этом списке есть и Nagios, который плавает между специалистами, пакетом и универсальным решением. Если вы помните, изначально Nagios был opensource’ным проектом для мониторинга структуры, сейчас это коммерческое решение, которое предлагает различные инструменты, включая NetFlow.

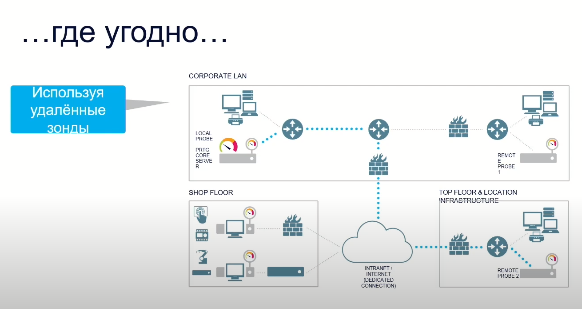
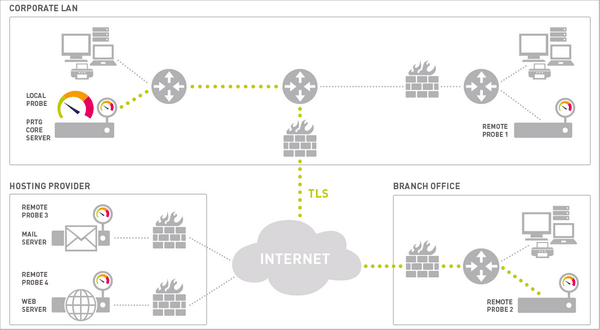
Теперь, раз уж мы заметили PRTG в этом списке, я бы зря приехал в Петербург, если бы не рассказал вам о нем подробнее. Это универсальное решение “для мониторинга всего”, как мы говорим. При помощи самых разных протоколов и методик мониторится самыми разными способами и везде, где угодно при помощи систем удаленных зондов. У нас нет агентов, мы ничего на конечные точки не устанавливаем, а, значит, развертывание такой сети не потребует каких-то существенных дыр в безопасности.
Мониторятся сети разного размера, потому что мы сканируем горизонтально. Дошли до верхнего предела производительности сервера — ставим рядом другой и так далее. И мы работаем, как сети отелей в южных краях, по системе “все включено”, то есть мы поставляем все функции системы в одной лицензии. Мы не можем физически вам продать какие-то модули и аддоны, даже если вы этого захотели. Удаленные зонды, наши сборщики метрик, в распределенных сетях поставляются в неограниченном количестве. В комплекте системы поставляется отказоустойчивый кластер — копия сервера, которая гарантирует вам всегда доступ к вашей системе.
И что очень важно, мы предлагаем поддержку из коробки экзотическим на сегодняшний день протоколам HL7 (это медицинский протокол). Вы можете включить в свою систему мониторинга абсолютно чуждую по принципам систему, по системам безопасности — медицину. Мониторить при помощи протокола DICOM все, что касается графической информации в системе здравоохранения (рентгеновские снимки, сканы 3D и т.д.). HL7 — протокол для обмена между различными субъектами современной больницы, специальный протокол, который пробился среди многих других, занял главенствующую позицию. И протоколы MODBUS, MQTT и OPC UA — пришельцы из производства, если оно современное (а мы говорим о цифровых двойниках, диджитализации). Такое производство может быстро развиться в отдельную IT-систему, которую тоже будет необходимо будет мониторить.

Немного о самом Paessler’е. Многие называют наш продукт Paessler, но продукт все-таки называется PRTG Network Monitor. Дирк Пэсслер — отец-основатель. Компания основана в 1997 году, находится в Нюрнберге. Порядка трехсот сотрудников из 25 разных стран, русскоязычных в том числе. Кстати, PRTG из коробки есть и на русском языке (всего поддерживается 10 языков). Наши клиенты — компании всех размеров, мы не выбираем между enterpris’ом и индивидуальными предпринимателями. Эта политика охвата всех, она привела нас к очень удобной позиции, что 70% компаний из списка Fortune 100 пользуются PRTG. Как я и сказал, есть штаб-квартира в Нюрнберге, есть офис в США и партнеры и региональные команды по всему миру. На сегодняшний день, является лидером в IT-мониторинге — более 300 000 установок по всему миру.
Если упомянуть разные порталы, которые занимаются оценкой программного обеспечения, то, согласно большинству версий, мы лидеры уже достаточно давно.

ВОПРОСЫ СПИКЕРУ:
1. — Здравствуйте! Вы сказали, что PRTG имеет возможность мониторить все, что угодно, без установки агентов на конечные устройства. У PRTG есть очень хороший зонд на Windows-системы. В концепции вы уходите от агентского мониторинга?
— У нас нет агентов. Зонд мониторит метрики на расстоянии. Если у вас есть несколько отдельных участков сети, через Интернет вы не можете мониторить. Вы устанавливаете в отдаленных сегментах сети зонды, которые по локальной сети, не нарушая безопасности, собирают метрики, на всякий случай кэшируют их и переправляют на сервер.
— Да нет. Вот есть Windows-сервер. Вы ставите зонд, у него есть возможность рестартануть службы на сервере при определенных правах. Чем это не агент? Да, он может отправлять запросы на другие хосты.
— Хорошо, я понял. Как вам ситуация. Ферма из 10 серверов. Только на одном из них установлен зонд, он мониторит сервера.
— Но можно поставить и 10 зондов на каждый сервер.
— Это инфраструктурный вопрос. Мы не рекомендуем мониторить с одной машины, зонд по умолчанию ставится, но чисто за хардами присматривать, непосредственно мониторинг сети выносится за скобки. Это позволяет перераспределять нагрузки. Во-вторых, как вы относитесь к идее взглянуть на наш roadmap и увидеть там мультиплатформенные зонды, например, на Linux’е. Такая мысль поначалу очень долго приживалась, исторически PRTG — Windows-система. Во время локдауна был написан на Python’е первый маленький зондик, который работал исключительно по SMNP и поддерживал всего 22 сенсора из 300 имеющихся. Теперь в roadmap появился, надеюсь, к концу года допилят, новый мультиплатформенный зонд. Он должен работать без ограничений. Третий вопрос: когда будет сервер PRTG на Linux? Могу сказать, нескоро. Но переход хотя бы зондов на Linux удешевит всю систему, но изменений в самой технологий мониторинга не ожидается. Как бы мы не трактовали зонд, оно все так и останется.
2. — Как вы оцениваете риски и случаи, что произойдет с заказчиком? Все мы помним Splunk.
— Вопрос мне понятен, можете не продолжать. Если мы вам продадим лицензию, лучей смерти у нас нет. Вы можете отрубить от Интернета, это серьезный плюс PRTG, что даже зарегистрировать вы его сможете, не выходя в Интернет. Это, конечно, не руководство к действию, тем не менее offline-активация есть. Естественно, это малоприятный фактор, что отключившись от Интернета, вы перестанете получать апдейты, но лицензия останется за вами. Мы не сможем у вас отозвать ее. Отрубите доступ в Интернет, она будет прекрасно локально у вас работать.
3. — Я все-таки хочу разобраться, что есть зонд, потому что чудес не бывает. Вы говорите, что зонд опрашивает клиентов, не трогая их самих, но каким образом он это делает? По SMNP? Надо настроить права доступа, что зонд мог забирать данные по SSH?
— Абсолютно верно.
— То есть какая-то настройка клиента нужна.
— Необходимость в настройке есть, но не клиента, потому что в SMNP, например, в 95% случаев настройки остаются по умолчанию.
— Community public в нормально настроенных системах не отдается наружу.
— Она и не должна работать наружу. Вот это первый фактор. Смотрите, здесь у нас сервер, на нем находится локальный зонд, который вам сразу из коробки дает возможность мониторить все, до чего дотягивается сервер локально. Потом вы начинаете добавлять сюда отдельные участки, здесь полноценный сервер вам не нужен, вам нужен компьютер, который будет нести на себе зонд. Это две службы, они выходят в трей. Они дистанционно добавляются, объединяются сервером и общаются по TLS-протоколу. Дальше сам по себе сенсор, датчики, они не крепятся к конечным системам. Они располагаются здесь, и для того, чтобы опрашивать данные, достаточно прав на чтение. Агент же становится системной службой, понимаете. Если вы скомпрометируете зонд, то ничего, собственно, не произойдет. Он обладает лишь правами на чтение.
— Я вас понял. Давайте возьмем, например, Zabbix-агент. Он работает с правами Zabbix, если ему не давать прав на удаленное выполнение команд и так далее, то то же самое. Вы не сможете поломать сервер. Но если мы имеем возможность выполнять какую-то команду в операционной системе, я сейчас про Linux говорю, например, с правами конкретного пользователя есть уязвимости ядра, которые позволяют, имея права локального пользователя, получить “рута”. Думаю, то же самое будет и с вашим зондом. Вопрос терминологии. Получается, зонд — это агент с ограниченными правами?
— Мы называем это сборщик информации, он не агент. Если сравнивать с Zabbix’ом.. представьте себе агент, установленный в систему, и в настоящий момент у него работы нет никакой. И тем не менее, на систему он установлен, он там постоянно находится, круглые сутки. Риск сбоя и взлома увеличивается во много раз. Если же у зонда нет работы по опросу метрик, то он и не дергает систему. Две разные вещи: резидент локальный и резидент экстерриториальный.
— Zabbix-агент, если его не просить, тоже не дергается…
— Но он установлен.
— Он просто работает как резидентная программа на сервере, но ничего не делает.
— То есть его нужно активировать запросом?
— Ему нужно дать запрос с сервера или прокси, чтобы он отдал какую-то метрику.
— Прекрасно. С терминологией понятно, это разные толкования. Теперь представьте себе, вот такую именно ситуацию, основанную на Zabbix’е. Между сервером Zabbix и массой конечных точек, где сидят агенты, находится достаточно нестабильный и очень опасный канал — Интернет. Здесь же, в PRTG, общение происходит локально.
— У Zabbix есть прокси, и, соответственно, есть центральный сервер, который собирает метрики, и мы можем в какую-то распределенную удаленную структуру поставить прокси. Он будет общаться с агентами локально, а метрики, собранные и положенные в прокси, могут спокойно через TLS возвращаться обратно в сервер. То есть тут вопрос: как удобнее? Можно мониторить через прокси, можно, если у нас есть внешний удаленный доступ к агенту, через агент. И то, и другое может через TLS.
— Нельзя умалять достоинства Zabbix. У зонда ещё есть две функции. Первая. Представьте, что один зонд переполнился, больше не тянет запросы. Вы добавляете еще один и просто дропом мышки перетаскиваете. На тот же хост не получится. Нужен отдельный или виртуальная машина. А что делает Zabbix с прокси, куда деваются собранные метрики в таком случае?
— Он может хранить какое-то время в себе собранные метрики. Время определяется выделенным на диске местом и конфигурацией. Я просто отметил, что ваш зонд похож на гибрид прокси и Zabbix-агента. А второе отметил, что у вас возможно линейное масштабирование. Можно включать в параллель зонды, что балансирует нагрузку. Это важная штука, спасибо!
— Все-таки, сфера действия одна и та же, естественно, идеи тоже очень похожи. Нельзя отрицать, что много похожего у наших конкурентов. Говорят мне партнеры в РФ, что Zabbix хорош для чего-нибудь относительно небольшого.
— Не соглашусь. Я как бы хотел понять, что такое зонд. Я получил представление.
4. — Зонд для сетевых устройств устанавливается на сервер?
— Он может быть установлен на любой носитель. Откуда-то системный ресурс нужно брать, из облака запросы не посыпятся просто так. Но это аксиома для всех. Если вы пользуетесь, например, решением PRTG в облаке, то сервер находится у нас, а у вас только зонд — вы арендуете мощность. Всего один контакт по одному единственному порту. Есть “за” и “против”, конечно. По статистике компрометации систем агентские системы существенно более уязвимы, чем “безагентские”. Если скомпрометирован единственный пароль, можно попрощаться со всей системой.
— Меня больше масштабирование заинтересовало.
— PRTG работает по системе строгой иерархии. На вершине сервер, под ним располагаются зонды, каждый из которых может содержать одну или много групп, группы могут содержать подгруппы и так далее. Потом идут системы, и сенсоры. Но на уровне серверов у нас масштабирование горизонтальное. И важно отметить, пока баланс и разброс между серверами — ручная история. Каждый сервер — одна консоль.
— Можно ли получить консолидированный данные в одном месте?
— Для этого у нас есть отдельная надстройка в enterprise-версии. Когда вы понимаете, что пятью серверами вы уже не обойдетесь, в какой-то момент вы потеряете контроль над всем этим, алертов и стримов будет очень много. Тут вступает в дело эта надстройка — это своего рода Uber-дашборд, который целиком собирает стрим с сервера, а вы можете на основе этого собрать дашборд в универсальных комбинациях, охватить пинги со всех 50 серверов, а можете охватить несколько метрик только с 25 серверов, находящихся в Европе. Мы ждем нового декстопного клиента, там будет много мультисерверных функций, включая перераспределение, миграцию.