Что такое Mean Time to Repair (MTTR)?
Среднее время восстановления (mean time to repair — MTTR) является важным показателем, который представляет собой среднее время, необходимое для ремонта и восстановления работоспособности компонента или системы. MTTR — это один из критериев ремонтопригодности систем, оборудования, приложений и инфраструктуры организации, а также эффективности ремонта этого оборудования при возникновении ИТ-инцидента.
Время восстановления отсчитывается от момента обнаружения сбоя и включает в себя время, затраченное на диагностику, ремонт, тестирование и любые другие действия до восстановления объекта. Низкий показатель MTTR указывает на то, что оборудование/сервис/услуга подлежит быстрому восстановлению и, следовательно, любые связанные с ним ИТ-проблемы окажут сравнительно меньшее негативное влияние на бизнес. Высокое значение MTTR свидетельствует о том, что отказ приведет к проблемам в обслуживании и серьезно повлияет на бизнес-процессы.
Согласно ZK Research, 90% MTTR тратится только на то, чтобы выяснить, действительно ли существует проблема. Неправильная диагностика или ненадлежащий ремонт также могут увеличить среднее время восстановления работоспособности. Высокое MTTR должно побудить ИТ-администраторов пересмотреть свой подход к устранению неполадок с пристальным вниманием ко всему циклу: от отслеживания и обнаружения неисправностей до методов диагностирования и устранения проблем.
Большинство соглашений о качестве обслуживания (SLA — service-level agreements) так или иначе устанавливают норму MTTR. Однако, важно помнить, что MTTR представляет собой типичное время ремонта, а не гарантированное. Поставщик, утверждающий, что среднее время восстановления (MTTR) составляет 24 часа, говорит, что именно столько времени обычно требуется для завершения ремонта, но для устранения определенных неполадок может потребоваться больше или меньше часов.
Основы MTTR
Что такое показатели отказов?
Метрики отказов — это индикаторы производительности, которые позволяют организациям отслеживать надежность своего оборудования и систем. Термин «отказ» относится не только к нефункционирующим устройствам или системам (например, к отказавшему файловому серверу), он также может обозначать работоспособные системы, которые намеренно отключены из-за снижения производительности. Любая система, работа которой не отвечает поставленным целям, может считаться отказавшей.
Общие показатели отказов включают:
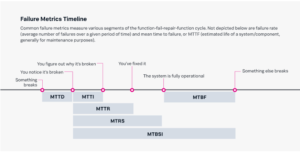
- Среднее время восстановления (mean time to repair — MTTR): среднее время восстановления неисправной системы. Это показатель ремонтопригодности компонента системы (услуги). В зависимости от сложности устройства и связанной с ним проблемы, среднее время восстановления (MTTR) может измеряться в минутах, часах или днях.
- Среднее время работы между отказами (mean time between failures — MTBF): среднее время работы между отказом одного устройства (системы) и следующим. Организации используют MTBF для прогнозирования надежности и доступности своих систем и инфраструктур.
- Среднее время наработки на отказ (mean time to failure — MTTF): среднее время, в течение которого устройство или система должны работать до отказа. Обычно ИТ-группы собирают эти данные, наблюдая за компонентами системы в течение нескольких дней или недель. Хотя MTFF похож на MTBF, MTTF обычно используется для описания заменяемых элементов (например, ленточный накопитель в резервном массиве), тогда как MTBF используется для элементов, которые можно и заменить, и отремонтировать.
- Среднее время обнаружения (mean time to detect — MTTD): среднее время между возникновением проблемы и ее обнаружением. MTTD обозначает промежуток времени до того, как ИТ-служба получит сообщение о неисправности.
- Среднее время расследования (mean time to investigate — MTTI): среднее время между обнаружением ИТ-инцидента и моментом, когда организация начинает исследовать его причину и решение.
- Среднее время восстановления обслуживания (mean time to restore service — MTRS): среднее время, прошедшее с момента обнаружения инцидента до того, как затронутая система или компонент снова станет доступным для пользователей. MTRS отличается от MTTR тем, что MTTR обозначает время, необходимое для ремонта элемента, в то время как MTRS показывает, сколько времени требуется для восстановления обслуживания конечных пользователей и после ремонта этого элемента.
- Среднее время между системными инцидентами (mean time between system incidents — MTBSI): среднее время, прошедшее между обнаружением двух последовательных инцидентов. MTBSI можно рассчитать, сложив MTBF и MTRS (MTBSI = MTBF + MTRS).
- Частота отказов: еще один показатель надежности, который измеряет частоту отказов компонента или системы. Выражается как количество отказов за единицу времени.
Показатели отказов важны для управления временем простоя и его потенциальным негативным влиянием на бизнес. Они предоставляют ИТ-отделам количественные и качественные данные, необходимые для лучшего планирования и реагирования на неизбежные системные сбои.
Чтобы эффективно использовать эти метрики, вы должны собрать большой объем конкретных точных данных. Выполнение этого вручную было бы утомительным и трудоемким, но современное корпоративное программное обеспечение может легко собирать необходимые данные и рассчитать эти показатели всего за несколько щелчков мышью.
Что такое надежность, доступность и ремонтопригодность?
Надежность, доступность и ремонтопригодность — RAM (reliability, availability and maintainability) — являются элементами проектирования системы, которые влияют на длину и стоимость жизненного цикла системы и ее способность выполнять поставленные задачи. Перечисленные показатели можно воспринимать как степень уверенности организации в своем оборудовании, программном обеспечении и сетях.
Каждый из этих показателей поможет выявить сильные и слабые стороны системы и их влияние на производительность, удовлетворенность клиентов и прибыль организации.
- Надежность можно определить как вероятность того, что система будет последовательно выполнять установленную функцию без сбоев в течение заданного периода времени. Однако все аппаратное и программное обеспечение подвержено сбоям, поэтому показатели отказов, такие как MTBF, MTTF и частота отказов, используются для измерения и прогнозирования надежности компонентов и системы в целом.
- Доступность — это вероятность того, что система работает так, как задумано, когда ее нужно использовать. Следовательно, это функция как надежности, так и ремонтопригодности, и ее можно рассчитать путем деления MTBF на сумму MTBF и MTTR (A = MTBF / (MTBF + MTTR)).
- Ремонтопригодность описывает легкость и скорость, с которой система и ее компоненты могут быть отремонтированы или заменены. Ремонтопригодность системы зависит от множества факторов, включая качество оборудования, квалификацию и доступность ИТ-персонала, а также адекватность и эффективность процедур обслуживания и ремонта. MTTR — это один из основных показателей, используемых для определения ремонтопригодности компонента или системы. Низкое значение показателя указывает на высокую ремонтопригодность.
В совокупности данные показатели можно использовать для определения времени безотказной работы (надежности) и простоя (ремонтопригодность) системы, а также процента времени ее безотказной работы за определенный промежуток времени (доступность).
Почему так важно значение среднего времени восстановления (MTTR)?
Поскольку MTTR указывает, как долго критически важные для бизнеса системы не обслуживаются, он является мощным средством прогнозирования влияния ИТ-инцидента на чистую прибыль организации.
Безусловно, технологические сбои неизбежны. Понимание MTTR дает организациям представление о том, насколько быстро и эффективно они могут реагировать на эти сбои и приводить систему в нормальное состояние.
В чем разница между средним временем восстановления (MTTR) и средним временем работы между отказами (MTBF)?
По сути, MTBF сообщает организации, как часто выходит из строя ее оборудование, в то время как MTTR указывает, как быстро работа системы может быть восстановлена. Однако эти показатели можно использовать вместе для расчета времени безотказной работы или доступности системы. Целью организации должно быть сокращение MTTR и увеличение MTBF, чтобы минимизировать количество незапланированных простоев.
Как рассчитывается среднее время восстановления (MTTR)?
MTTR рассчитывается путем деления общего времени простоя, вызванного отказами, на общее количество отказов. Если, например, система выходит из строя три раза в месяц, и в результате сбоев в общей сложности простаивает шесть часов, среднее время восстановления (MTTR) составит два часа.
MTTR = 6 часов / 3 сбоя = 2 часа
Хотя ремонт может занять минуты или дни, в зависимости от серьезности неисправности, среднее время восстановления ИТ-систем обычно измеряется часами.
Применение значения среднего времени восстановления (MTTR)
Что такое MTTR в ITIL?
MTTR — это ключевая метрика, включенная в библиотеку ИТ-инфраструктуры (IT Infrastructure Library). ITIL — это серия рекомендательных положений, в которых подробно описаны передовые практики для лучшего согласования управления ИТ с потребностями бизнеса.
ITIL разбивает ИТ-функции на несколько измеримых процессов, включая управление каталогом услуг, управление уровнем обслуживания, управление рисками, управление мощностями, управление доступностью, управление непрерывностью ИТ-услуг, управление соответствием, управление ИТ-архитектурой и управление поставщиками.
Среднее время восстановления рассматривается как часть процесса управления доступностью, целью которого является обеспечение соответствия всей ИТ-инфраструктуры, процессов, инструментов и ролей согласованным целям доступности (agreed availability targets). MTTR указывается вместе с MTBF, MTBSI и MTRS как показатель для управления инцидентами и проблемами, которое может быть включено в соглашение об уровне обслуживания (service level agreement — SLA).
Что такое среднее время восстановления (MTTR) в DevOps?
В DevOps (где MTTR обычно расшифровывается как mean time to recovery) MTTR используется для измерения того, сколько времени требуется команде DevOps для восстановления системы после производственного сбоя. В таком случае MTTR обычно рассчитывается как среднее время простоя производства за последние 10 простоев. Метрики необходимы и для расчета количественной оценки успеха DevOps — в идеале значение показателя будет сокращаться по мере внедрения DevOps в организации.
MTTR также может быть полезным для информирования руководителей и других руководителей бизнеса о положительном влиянии DevOps на бизнес, если перевести время в доллары, сэкономленные за счет повышения производительности и сокращения времени простоя.
Какова роль среднего времени восстановления (MTTR) в процессе развития компании?
MTTR используется как один из показателей стабильности процесса непрерывного развития организации.
Скорость разработки и доставки программного обеспечения является жизненно важным фактором успеха большинства организаций. Надежный непрерывный процесс доставки включает в себя цикл обратной связи «построение, измерение, обучение» (“build, measure, learn”), что способствует достижению бизнес-целей.
Поскольку скорость и стабильность являются основой непрерывного развития, важны показатели, которые помогают оценивать и улучшать их значения. Стандартизированных показателей для непрерывного развития не существует, каждая организация должна решить, какие показатели подходят для ее целей. MTTR обычно используется для оценки того, насколько быстро группы могут устранять сбои в конвейере непрерывной доставки и повышать стабильность работы системы.
Как снизить среднее время восстановления (MTTR)?
Большинство проблем, приводящих к высокому среднему времени восстановления, будут специфичны для каждой организации в отдельности. Однако существует шесть общих шагов по снижению среднего времени восстановления, которые принесут пользу любому бизнесу:
- Анализируйте инциденты: чтобы начать сокращать MTTR, вам нужно лучше понимать инциденты и сбои, происходящие в системе. Современное корпоративное программное обеспечение поможет вам в автоматическом объединении разрозненных данных для получения надежных значений MTTR и получения ценной информации о причинах сбоев.
- Обязательно занимайтесь мониторингом: прежде, чем вы сможете решить проблему, вам нужно определить ее. Хорошее решение для мониторинга предоставит вам непрерывный поток данных о производительности вашей системы в режиме реального времени и будет предупреждать вас о любых проблемах по мере их появления.
- Имейте план действий. Компании, успешно прошедшие полную цифровую трансформацию, могут использовать более гибкий подход, используя кросс-функциональные инструменты совместной работы и реагируя на каждый инцидент с учетом его специфики. Каким бы ни был ваш план, убедитесь, что в нем четко указано, кого уведомлять о возникновении инцидента, как задокументировать инцидент и какие шаги стоит предпринять в работе над решением проблемы.
- Автоматизируйте свою систему управления инцидентами. Первое, в чем нужно убедиться, что нужные люди быстро получат точную информацию о проблеме. Автоматическая система управления инцидентами может отправлять многоканальные оповещения — телефонный звонок, текстовое сообщение, письмо на электронную почту — всем назначенным сотрудникам одновременно, что значительно экономит время.
- Назначьте группы и роли реагирования. Четко определенные роли и обязанности имеют решающее значение для эффективного реагирования на инциденты и снижения среднего времени восстановления работоспособности. Хотя структура поддержки будет определяться потребностями вашего бизнеса, ITIL предлагает такое распределение ролей:
-
- Инцидент-менеджер: сотрудник на этой позиции отвечает за процесс управления инцидентами, адаптируя и улучшая его по мере необходимости. Согласно ITIL, обязанности инцидент-менеджера в малых и средних предприятиях может выполнять менеджер службы поддержки, а в больших компаниях это отдельная позиция. На плечах этого сотрудника основная ответственность за обеспечение корректной работы системы управления инцидентами. Он также возглавляет группу реагирования, отслеживает ключевые показатели эффективности (KPI) и управляет поддержкой первого и второго уровня.
- Поддержка первой линии (уровень 1): эта роль является точкой контакта с конечными пользователями, сообщающими о сбоях в обслуживании. Она отвечает за классификацию инцидентов и первичные попытки быстро восстановить отказавший сервис. Если служба поддержки первой линии не может решить проблему, эта группа должна направить ее соответствующему персоналу поддержки второй линии, отследить действия по ремонту и информировать пользователей о статусе инцидента.
- Поддержка второй линии (уровень 2): технические специалисты второго уровня обычно обладают более глубокими знаниями, чем сотрудники поддержки первого уровня. Поэтому они могут быть привлечены для устранения инцидентов, которые не может решить первая линия поддержки. Также поддержка второй линии может нести ответственность за взаимодействие со сторонними поставщиками программного обеспечения или оборудования, чтобы помочь быстро восстановить нормальное обслуживание. В больших и сложных системах может потребоваться группа поддержки третьей линии (уровень 3) с еще более продвинутыми навыками и знаниями.
Ваша группа реагирования на инциденты необязательно должна выглядеть именно так. Но какую бы структуру вы не решили использовать, убедитесь, что все члены команды четко понимают свои обязанности и в ней присутствует назначенный руководитель, который наблюдает за реагированием на инциденты и обеспечивает тесную связь с заинтересованными сторонами внутри и за пределами команды.
-
- Обучите членов команды разным ролям: наличие специалистов, специализирующихся на определенных вопросах, бесценно, однако существует риск взвалить на них огромный объем работы, что снизит качество и скорость выполнения обычных обязанностей, а в конечном итоге может привести к эмоциональному выгоранию сотрудников. Такой подход также сковывает вашу команду, если этого специалиста не будет на месте во время инцидента, могут возникнуть новые сложности.
Вы можете воспользоваться этими рекомендациями и снизить значение MTTR. Важно убедиться, что все члены команды глубоко понимают вашу систему и обучены нескольким ролям, так вы будете эффективны в реагировании на инциденты.
Высокая видимость вашей инфраструктуры поможет вам быстрее и точнее диагностировать проблемы. Например, данные в реальном времени об объеме входящих запросов сервера и о том, как быстро сервер отвечает на них, лучше подготовит вас к устранению неполадок в случае сбоя этого сервера. Данные также позволяют увидеть, как конкретные действия по ремонту отдельных элементов влияют на производительность системы, чтобы вы могли быстрее разработать соответствующее решение.
Заключение
MTTR может сильно повлиять на ваш бизнес.
Поскольку корпоративные ИТ-службы вынуждены повышать уровень обслуживания при одновременном снижении затрат, критически важным становится время реагирования на инциденты. MTTR — надежный показатель способности организации быстро реагировать на потенциально дорогостоящие проблемы и устранять их. Учитывая прямое влияние простоя системы на производительность, прибыльность и доверие клиентов, четкое понимание MTTR и его функций необходимо для любой технологически ориентированной организации.