Аутсорсинг и кастомизация Zabbix: централизация, сопровождение и развитие платформы
Коробов Денис, Лукиных Александр [X5 Tech]
Расшифровка видео с доклада на Big Monitoring Meetup 9, состоявшегося в Санкт-Петербурге, все мероприятия сообщества Monhouse:
Меня зовут Лукиных Александр, я начальник Управления централизованного мониторинга X5 Технологий. Со мной мой коллега Коробов Денис, руководитель команды разработки направления сервисного мониторинга и транспорта данных.
Сегодня мы с вами будем говорить о Zabbix. Такая система как Zabbix в основном находится в состоянии, которое не отвечает тем требованиям, которые мы сейчас ставим перед инфраструктурой и сервисами. Обычно это система, которая где-то там стоит под столом, кто-то ее по чуть-чуть «вертит» на 30-50% и параллельно занимается какими-то своими делами.
Соответственно, у нас, как у Управления централизованного мониторинга, родилась чудесная идея, почему бы нам не собирать и не приводить в порядок эти системы, не развивать их дальше и не превращать в такой сервис, который был бы полезен для всех?
В докладе мы расскажем, почему Zabbix — мощная, удобная и стабильная платформа. Поговорим про наше управление, чем мы занимаемся вообще, а также немного о масштабе того, почему у нас много инстансов Zabbix, и чем обусловлена такая необходимость.
Далее, мы коротко опишем, какие у нас есть системы, насколько они большие и перейдем к тому, с какими проблемами мы сталкиваемся. Это больше проблемы коммуникаций и межличностных отношений между командами, нежели технические кейсы. Т.е., что происходит, когда мы приходим и говорим: “Мы хотим сопровождать ваш Zabbix”.
Затем, мы познакомим вас с внутренней презентацией, в которой мы объясняем командам, как будет проходить процесс сопровождения, что мы будем делать с системой и как мы будем выстраивать взаимоотношения между командами.
Ещё мы познакомим вас, пожалуй, с самым интересным инстансом Zabbix, который поддерживает команда DevNet – сетевые автоматизаторы. Такие полуразработчики, полусетевики. Обязательно затронем проблемные кейсы общего плана.
В конце разберемся с Zabbix команды DevNet — про интеграцию системы и про то, как можно использовать эту систему нестандартными способами.
Управление централизованного мониторинга.
Функция нашего управления и вообще сами задачи, то есть централизация функций мониторинга и создание центра компетенции появились достаточно недавно. Мы работаем примерно год, но за это время мы достигли высоких результатов.
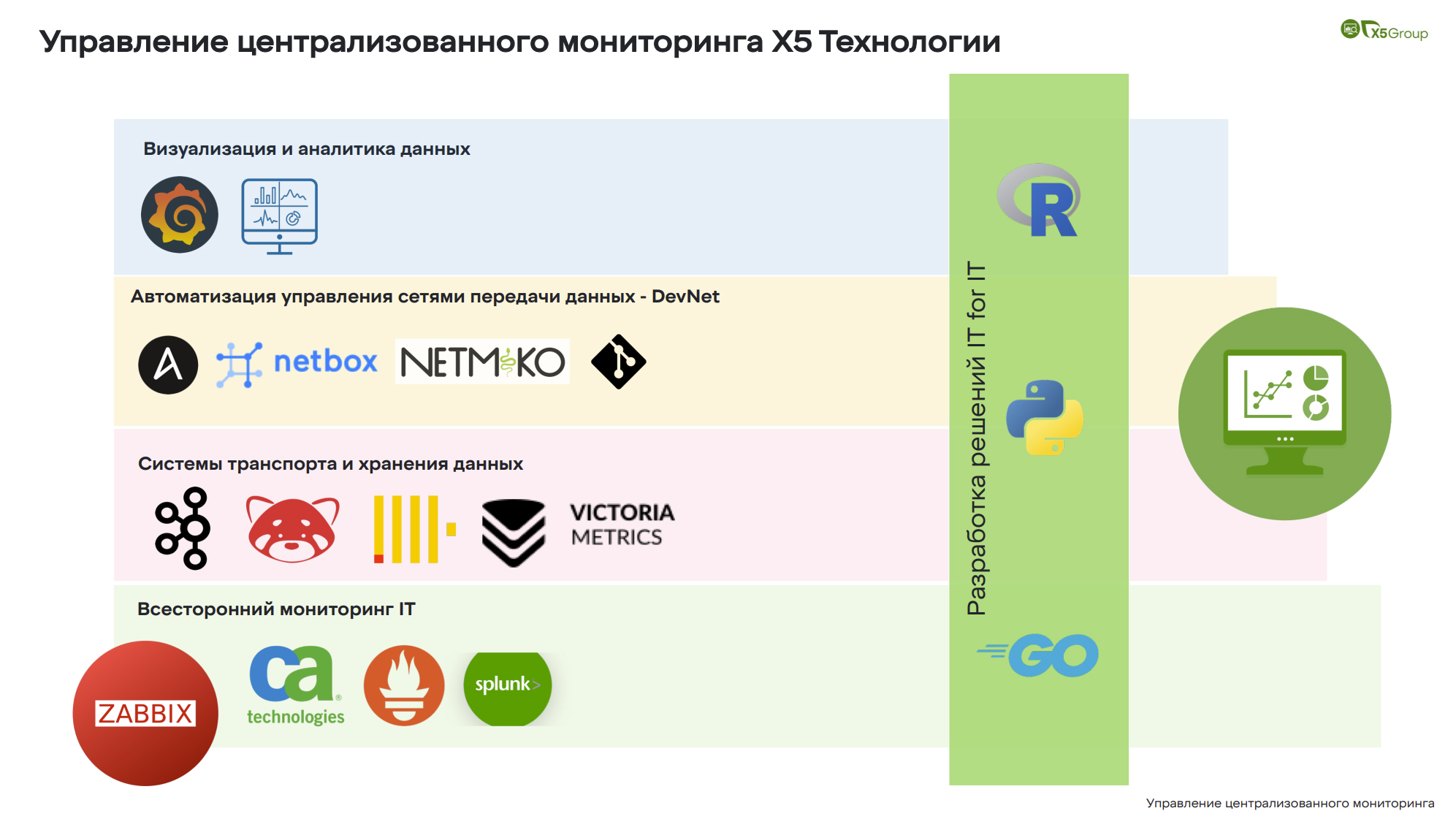
Что входит в наше управление?
- Группа визуализации и аналитики данных разрабатывает шаблоны, правила и методологии по построению графических дашбордов под заказ: как они должны выглядеть и какую информацию отражать. Кроме того, команда занимается бизнес-мониторингом, мониторингом бизнес-операций и разработкой аналитических отчетов.
- Команда DevNet — служба автоматизации сети. Все крутится через создание «источника правды» и различного рода механизмов автоматизации управления сетями.
- Группа системы транспорта и хранения данных отвечает за транспорт данных и сервисный мониторинг. Команда занимается настройкой и обслуживанием высоконагруженных брокеров сообщений и обслуживанием TSDB. Здесь у нас представлены Kafka, Red Panda. Тут же ClickHouse, VictoriaMetrics. VictoriaMetrics может быть и как база, и как непосредственно система мониторинга. Мы стараемся их поддерживать и развивать.Почему нужна отдельная группа для сопровождения таких сервисов? Здесь всё должно быть просто – развернул и работает, но когда мы говорим о сборе сообщений, сборе логов со 100-150 тысяч касс, которые каждую минуту генерируют огромное количество сообщений и различного рода технической информации… Уже возникают вопросы: как такое поддерживать, как такое хранить и анализировать?
- Основное направление деятельности — всесторонний мониторинг IT. Конечно, здесь выделен наш сегодняшний гвоздь программы, да, Zabbix. Помимо него, у нас есть инсталляции от CA Technologies, Prometheus и несколько корпоративных инстансов Splank’а. Компания, конечно, покинула рынок еще, по-моему, в 18-19-м году, но все еще надежно работает и как система логирования, и как система мониторинга.
Масштаб мониторинга: распределенная ИТ инфраструктура Х5
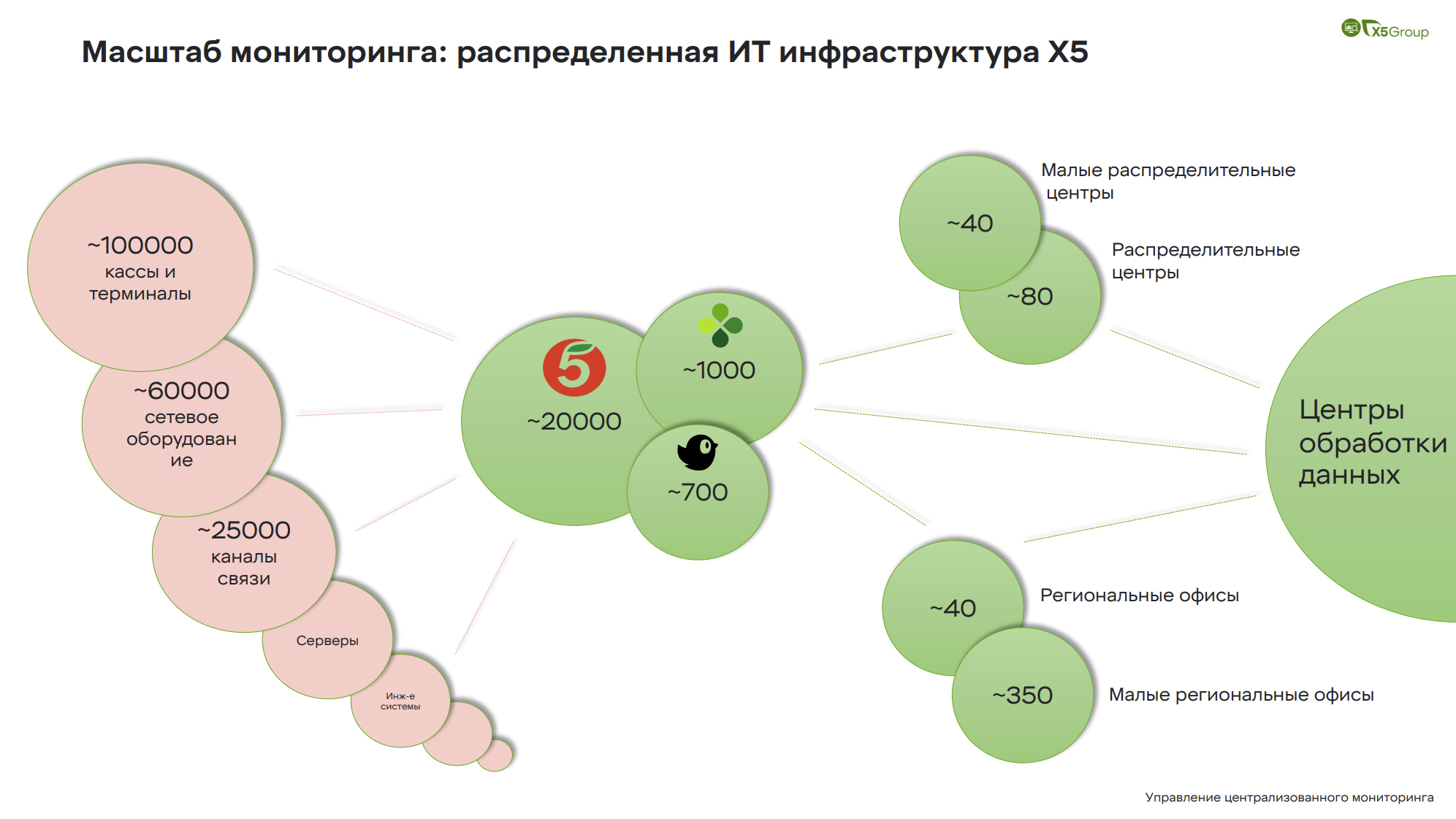
На слайде вы видите масштаб того, что мы мониторим. Здесь представлена распределенная инфраструктура: магазины, распределительные центры и офисы.
Если мы говорим о магазинах Пятерочка, например, то это около 20 тысяч объектов. Внутри каждого магазина находятся не только кассы, но и серверное оборудование, сетевое оборудование, различного рода периферия. Все это требует мониторинга, требует того, чтобы этот мониторинг работал хорошо, чтобы он отражал реальную картину.
На слайде не отражены ЦОД, где размещаются приложения и облака, представленный масштаб можно смело умножать на 2, чтоб получить тот ИТ-контур, который нам необходимо сопровождать с точки зрения мониторинга.
Ну, и про наши Zabbix’ы – передаю слово Денису.
Системы Zabbix сопровождаемые командой нашего управления
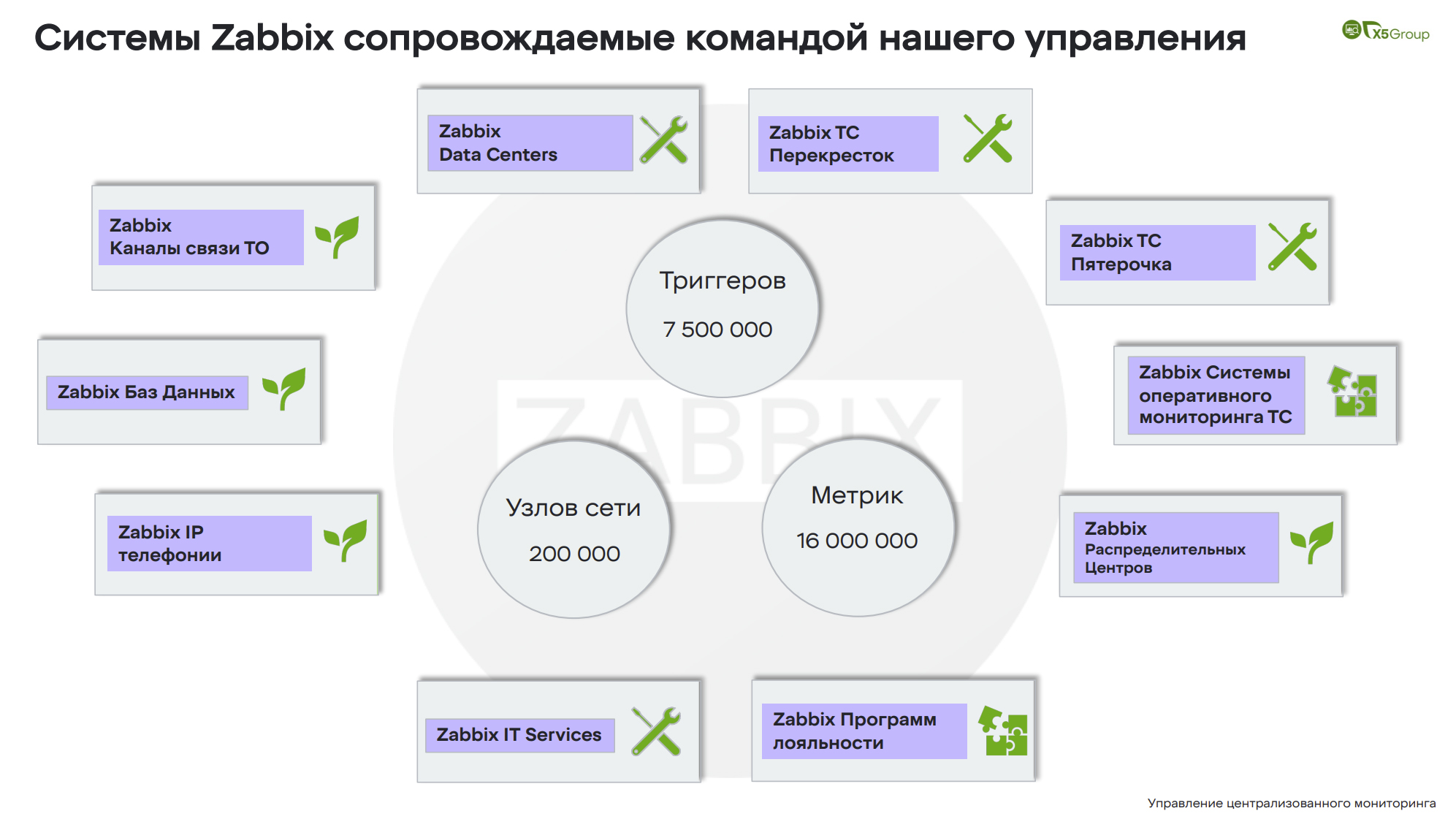
В нашем подразделении находится на поддержке 10 систем. Это всего лишь 200 тысяч узлов сети и порядка 16 миллионов метрик. Они все тригерятся примерно 7,5 миллионов раз, на что мы получаем алерты. Немного поподробнее про каждую из систем: как они работают, что за ними скрывается и за что они отвечают.
Система первая это “перекресток” и “пятерочка”. Я думаю, здесь понятно. Они позволяют слышать чудный голос пятерочки в магазинах, поддерживают экраны, биотерминалы, весы и другое оборудование.
- Zabbix как система оперативного мониторинга транспортных средств отвечает за самое важное. Чтобы в магазинах всегда были на полках продукты, машины доехали из точки А в точку Б. Смотреть за ними позволяет именно этот Zabbix.
- Zabbix распределительных центров отвечает за бизнес-операции внутри распределительных центров, чтобы каждая коробка была правильно отсканирована, база данных не подвисла и все работало корректно.
- Zabbix баз данных программ лояльности позволяет начислять всем баллы лояльности.
- Zabbix IT сервисов мониторит внутри компании все системы, которые находятся на поддержке, что позволяет всем порталам работать в штатном режиме.
- Zabbix IP-телефонии не требует представления.
- Zabbix баз данных у нас покрывает и Oracle, и MySQL, и другие базы данных Clickhouse, даже Arango, насколько я помню, мы поддерживаем.
- Zabbix каналов связи торговых объектов позволяет всем магазинам находиться на связи, чтобы не отваливались платежные терминалы и другие штуки.
- Zabbix Data Centers работает непосредственно с самими дата-центрами, чтобы все наши внутреннее окружение, все наши сервера работали корректно.
Таким образом, мы сталкиваемся с большим количеством возражений и опасений.
Основные опасения исходят от технологических команд в процессе передачи
Ну, вроде бы “Что такого?”. Вы приходите и говорите “Будем сопровождать ваш Zabbix”. А это та самая система где много красных триггеров, ничего не настроено, куча шаблонов, самописных скриптов, это всё работает нестабильно, это все не понятно.
Пять ключевых моментов, с которыми мы сталкиваемся:
1. Во-первых, это проблема формализации технического задания. Мы можем находиться на двух гранях некой плоскости. В первой части, когда присутствует некоторая недосказанность, мы можем что-то сделать, но потом к нам приходят люди и говорят: «Ребята, но это вообще не то, что мы хотели». А на второй грани мы что-то делаем качественно, уже прошло какое-то время, но команды, отвечающие за систему приходят и бесконечно ставят нам задания. Цикл разработки-доработки становится бесконечным.
Как мы от этого избавились? Мы стали рассматривать саму передачу системы к нам на сопровождение, как проект, в рамках которого происходит определенный набор процессов, как сопровождения, так и начальной проработки технического задания. Мы запускаем этап инициации проекта, в конце которого мы выходим на четко сформулированное техническое задание и на так называемый устав. Мы формируем документ, мы чётко на берегу определяем, что должно быть сделано.
2. Далее, наверное, самый интересный момент — риск потери рабочего места. Есть люди, которые боятся, что мы заберем систему мониторинга, а что им делать в этой ситуации?
Если ты сетевик или занимаешься базами данных, пожалуйста, занимайся. Систему мониторинга мы возьмем на себя, она будет отвечать всем твоим требованиям. Мы всегда проповедуем гибкий подход, мы за сотрудничество. Хотите, чтобы мы наполняли систему? Хотите, чтобы мы разработали скрипты, которые будут автоматически наполнять вашу систему, синхронизировать данные? Окей. Не хотите? Пожалуйста, наполняйте сами. Наша задача обновить систему, сделать ее безопасной, чтобы она соответствовала требованием ИБ и была отказоустойчивой.
3. Следующий пункт вытекает из первого — «Вы сломаете нам систему, мы потеряем данные либо мы потеряем контроль над системой». На самом деле, мы проводим полную ревизию технологического контура Zabbix и предлагаем различные решения по декомпозиции компонентов для улучшения стабильности.
Так же, как я и сказал ранее, мы заносим весь технологический контур наших коллег в реестр дополнительной проверки информационной безопасности. В свете последних событий, могу сказать, что Zabbix классная система, если за ним следить. Если за ним не следить, это система, которая полна дыр.
4. Ревизия инфраструктуры и взаимодействие с профильными технологическими подразделениями. Здесь речь идёт о следующем. В нашей компании, не знаю как у вас, есть следующая практика: если вам выделили какие-то мощности, например, виртуальную машину с вашей системой, то за поддержку этой системы могут отвечать профильные подразделения: Linux team, SRE team.
В то же время за базами данных, может смотреть группа поддержки баз данных. Мы, анализируя систему, возобновляем эти отношения, где были сделаны backup, где backup не были сделаны, что находится в Puppet-манифестах. Вот такие проблемы мы решаем, чтобы система превратилась в настоящий стабильный корпоративный сервис, а не сервис сделанный на коленке.
5. Проблемы неформальных связей, либо отсутствие каких-либо формальных связей со службами технической поддержки. Часто бывает так, что система замкнулась сама в себе. Кроме сопровождающего её инженера о ней никто не знает: ни служба быстрого реагирования, ни служба горячей линии, ни служба поддержки.
Так как мы являемся одним из основных, наверное, поставщиков инструментов для служб поддержки, мы можем выстроить эти процессы для наших коллег. То есть инцидент-менеджмент, проблем-менеджмент, ивент-менеджмент, мы можем все это прикрутить к вашей системе.
Последнее (у нас, конечно, такого не бывает) — ситуация, когда система есть на бумаге, но по факту она ничего не делает. Система не работает, но об этом позже расскажет Денис.
Процедура передачи системы на внешнее сопровождение
Когда мы приходим к коллегам, чтобы забрать систему, возникает вопрос: «Зачем вы это хотите делать?». Я всегда отвечаю, что так экономятся FTE. На поддержку обычной системы тратится порядка 1,5 FTE, мы же тратим 0,1-0,2 FTE для крупных инсталляций, потому что у нас процесс налажен.
Выгоды и возможности
Мы обеспечиваем контроль версий, поддерживаем серверы в актуальном состоянии. Тут же проводим проверки ИБ и приводим сервер в состояние, соответствующее корпоративной политике, это очень большой бич для многих систем. Подготавливаем её к интеграциям, в том числе с зонтичной системой мониторинга. Подготавливаем дашборды. Делаем мониторинг мониторинга, чтобы пользователи знали, что система работает корректно. Обязательно предлагаем возможность интеграции с личными корпоративными чат-ботами, чтобы можно было оперативно смотреть, что происходит с системой. Также предлагаем интеграцию с Zabbix-порталами компании.
Типы миграции

На предыдущем слайде, где были 10 наших систем, у каждой системы стоял свой значок. Это типы миграций, которые мы используем при принятии систем на поддержку. Их у нас существует три: Greenfield, Brownfield и Слияние.
Самый любимый наш — это Greenfield. Потому что мы берем чистую систему, доводим ее до правильных корпоративных стандартов, обновляем и начинаем поэтапное наполнение, согласно требованиям от внутреннего заказчика. Самый лучший тип миграции, который только может быть.
Если мы говорим про Brownfield, это самый сложный тип, когда мы приводим систему к соответствию. Здесь иногда всплывают такие вещи, что мне уже жарко 😉
Слияние. Если система маленькая и соответствует другим нашим системам, мы ее просто поглощаем, даём отдельное пространство и работаем с ней.
Что возникает с теми ресурсами, которые есть у команд, где развернуты системы? Обычно они переходят точно так же в нашу поддержку, чтобы мы могли как технические владельцы отвечать за безопасность этих систем, устанавливать обновления, выстраивать коммуникации с другими отделами и устранять чужие поломки. Так происходит не всегда — иногда команды оставляют за собой это право.
Процесс передачи, развития и поддержки систем Zabbix
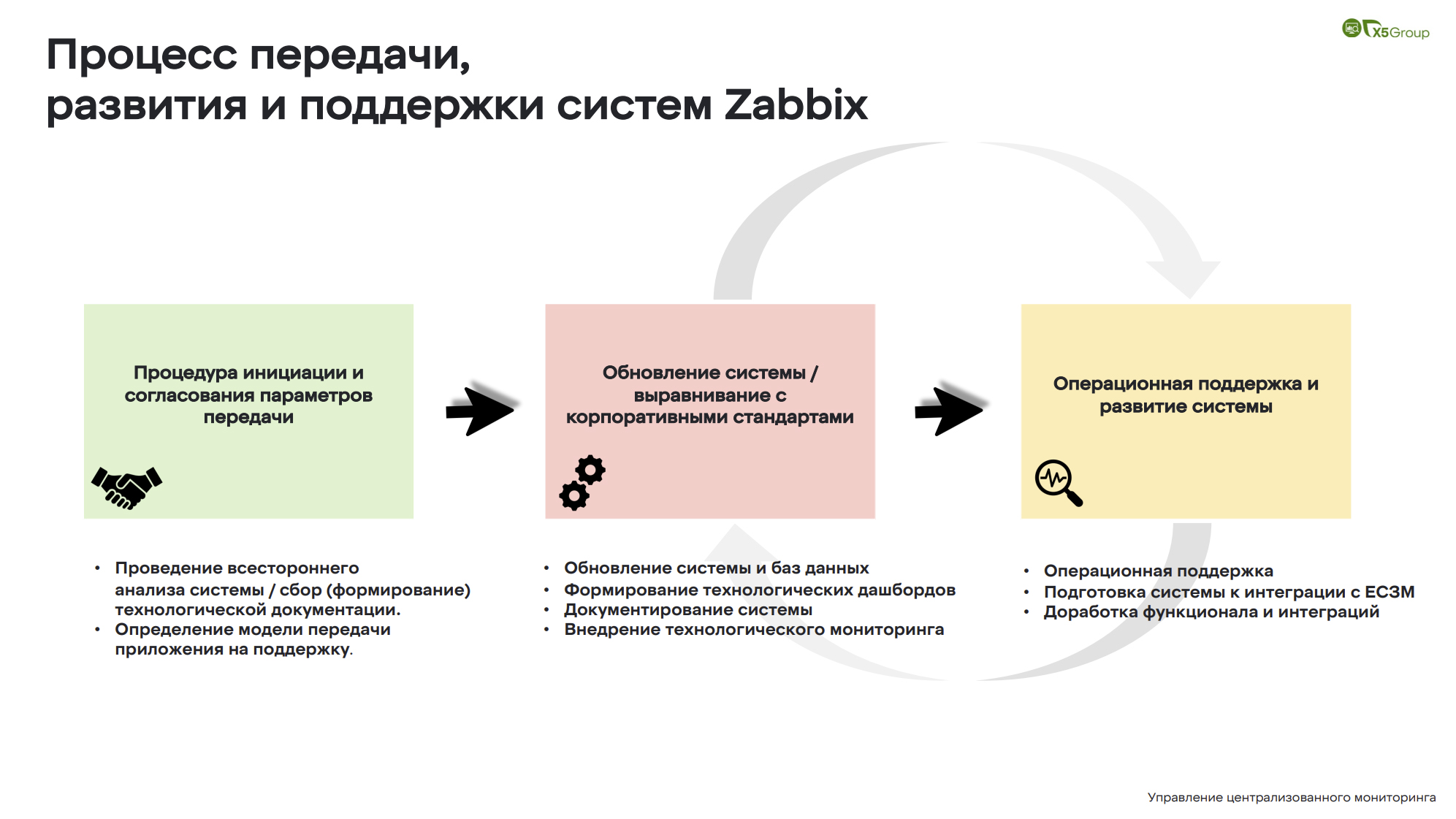
Как происходит сам процесс передачи развития Zabbix на поддержку? Ну, во-первых, мы садимся за стол переговоров. Мы обсуждаем все моменты и пытаемся докопаться до скрытых и потаенных дел, которые там происходят. Как только этот этап пройден, мы переходим к обновлению и выравниванию с корпоративными стандартами. Обратите внимание, это циклический процесс, ведь когда система перешла в нашу поддержку на полноценное развитие, мы сталкиваемся с тем, что выходят новые версии баз данных, Zabbix’ов, прокси, скриптов, языков программирования, плагинов и т.д. Мы проверяем их, смотрим необходимость такого обновления и опять попадаем в красный квадратик обновления системы. Опять ее выравниваем с корпоративными стандартами. Поэтому процесс у нас максимально циклический.
Процедура инициации и согласования параметров передачи
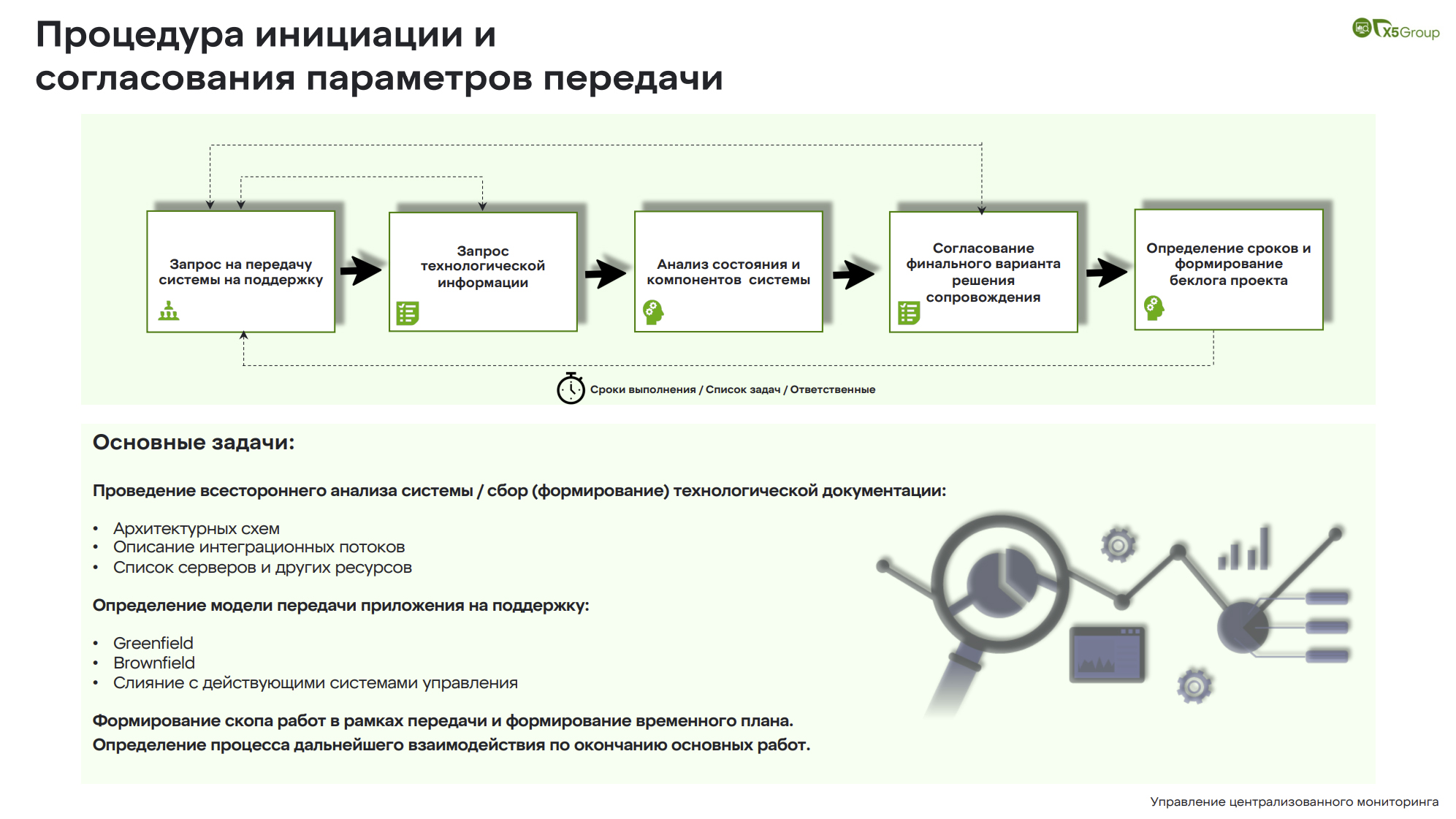
Теперь про каждый этап отдельно. Когда мы сели за стол переговоров, мы начинаем общаться относительно хотелок. Что же мы хотим получить в конечном итоге?
Когда этот этап завершен, переходим к технологической конфигурации. Смотрим всю техническую сторону: что за архитектурная схема, какие сервера, версии серверов, потоки, интеграции.
Далее анализируем сами компоненты: что происходит, какие алерты отправляются, как они отправляются, кто является пользователями системы.
Затем, мы составляем наше финальное предложение по типу миграции.
На выходе команда получает дорожную карту, в которой прописаны: исполнитель, список задач, который будет сделан, и срок данного исполнения. Все это позволяет человеку понимать, что он получает и как оно будет реализовываться. Это исключает эффект «чёрного ящика» – отдал, а что там с ней случилось, неизвестно.
Обследование системы
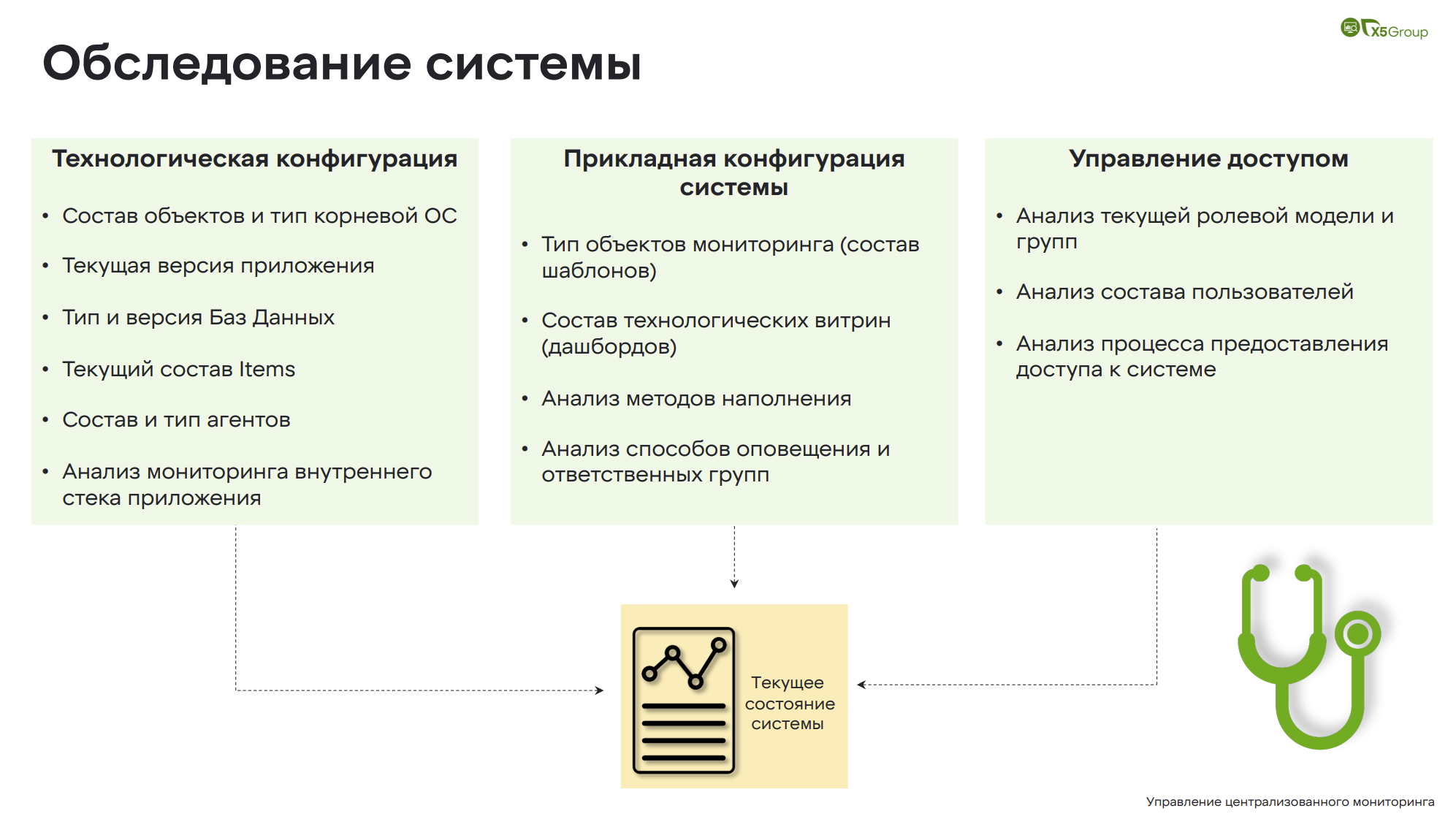 Обследование системы — это самый трудоемкий процесс, поэтому он разделен на три части.
Обследование системы — это самый трудоемкий процесс, поэтому он разделен на три части.
Первая — это технологическая конфигурация. Следующая идёт прикладная и вишенка на торте — это управление доступом.
В технологической части мы изучаем:
- состав объектов и тип корневой ОС;
- версии приложений и баз данных;
- состав Items;
- состав и типа агентов;
- анализ мониторинга внутреннего стека приложения.
В прикладной конфигурации мы смотрим сами шаблоны, потому что здесь бывает много чего придуманного другими подразделениями. Анализируем методы наполнения и способы оповещения, ответственных.
Управление доступом. Здесь есть пользователи, которые не заходили более двух лет. Как получается доступ? Зачем доступ к этой системе? Кто является пользователем? Как происходит наполнение системы пользователями? На все эти вопросы мы должны ответить в момент обследования, чтобы потом не возникло неприятных сюрпризов.
Операционная поддержка и развитие системы
Переходим к операционной поддержке. Будем считать, что наполнение происходит нашими силами и мы это делаем через заявки. То есть команда заводит заявки, мы производим наполнение. Все довольны, во все SLA мы укладываемся. Возможно также наполнение самим клиентом, потому что он лучше знает, какие системы у него находятся на мониторинге, что именно нужно мониторить. Мы контролируем и просим вносить некоторые наши правки, чтобы все соответствовало корпоративным стандартам.
При сопровождении кодовой базы мы стараемся ее минимально трогать, если те мамонты, которые зарыты в ней, при приезде не сломались — уже хорошо, мы приступим к этому, когда будем непосредственно поддерживать систему. Поэтому мы стараемся это делать все максимально аккуратно, а переписать код можно на моменте поддержки.
Всестороннее развитие системы. Это внедрение утилит обнаружения, наполнения, интеграции и диагностики, чтобы было видно как все происходит. Если требуется доработка и кастомизация, они заводят нам RFA и в рамках этого все выполняется.
Интеграции и подключение к ЕСЗМ (Единая Система Зонтичного Мониторинга)
Мы стараемся сразу, при принятии системы на поддержку, заложить все правила, требуемые для системы зонтичного мониторинга. Чтобы процесс проходил быстрее и легче, мы включаем его в очередь. Он попадает в какую-то из волн, где все наши практики применяются, чтобы все работало легче.
У нас сейчас идет очень большой проект, совместно с нашими партнерами из Monq и ЛАНИТ по внедрению единой зонтичной системы мониторинга. Хочу поделиться с вами некоторыми своими впечатлениями и наблюдениями по такой интеграции.
О чем здесь вообще речь? Если мы систему сопровождаем, она в хорошем состоянии, она отражает действительность. Но когда вы интегрируете 20-30 таких систем, если они плохо наполнены и плохо работают, ни о какой зонтичной системе мониторинга речи быть не может. Одна проблема в ресурсно-сервисной модели, которая строится с помощью такой системы, может повредить всю консистентность данных. И ни о каком запуске искусственного интеллекта и предиктивного анализа не может быть и речи.
Если система находится у нас на сопровождении, она готова, то мы сразу помогаем её интегрировать. Но если нет, то вы будете делать это своими силами, или с нашей помощью, но это будет намного дольше.
Проблемные кейсы
Теперь про проблемные кейсы. Когда мы производили раскопки, мы встречали
массу различных кейсов. Я постарался выделить три из них, которые больше всего запомнились.
Кейс 1: проблемы нестандартного стека разработки
Нестандартный стек разработки, какая здесь проблема? Был нестабильно действующий мониторинг, он не работал должным образом, причем не работал он на 7000 объектов.
Мы не могли понять, в чем дело. Заказчик предложил добавить еще один прокси сервер, при исследовании которого, мы нашли скомпилированный бинарник. Позже выяснилось, что это скрипт на Rust. Владельца и назначение скрипта никто не знал, но именно он работал нестабильно.
Прокачались в Rust, переписали все на Go, задокументировали, выложили, все работает как часы. Все отлично, проблемы решили.
Кейс 2: проблемы бесконечного цикла
Следующая проблема — бесконечный цикл. Прекрасная система, в которой все работало изумительно. Случайным образом обратили внимание на то, что одна из метрик постоянно отсвечивает единицей. Даже если принудительно класть систему, все равно возвращается единица. Исторические значения проверили и то же самое — единица.
Разобрались, в чем дело, была допущена досадная ошибка: система уходила в бесконечный цикл и всегда возвращала единицу. Было очень обидно, мы все переделали, убрали бесконечный цикл. Все заработало корректно и стало отражать текущую картину.
Кейс 3: выполнение неоптимальных SQL Selects
Самый крупный кейс: 100 тысяч проверок баз данных. Это наша старая система, в ней все было реализовано таким образом: написан скрипт, который выполняет километровые запросы для того, чтобы выяснить, все ли в порядке с базами данных, нет ли там каких-то фризов, деградации и прочего. Он работал нестабильно и мог негативно влиять на работу кассовых узлов.
Что мы сделали? Расследовали и обнаружили, что нет нужды использовать скрипт, если есть стандартный метод — Zabbix мониторинг баз данных. Переделали на него, все заработало как часы, нагрузки на кассы нету, все отлично.
Не нужно изобретать велосипед, обычно уже все придумано за нас.
Интеграция и кастомизация системы Zabbix командой DevNet
Одна из систем у нас – Zabbix NOC, которая отслеживает все каналы связи и предоставляет информацию о состоянии объектов, с которыми мы больше всего экспериментировали. Поэтому начнем с примера интеграции.
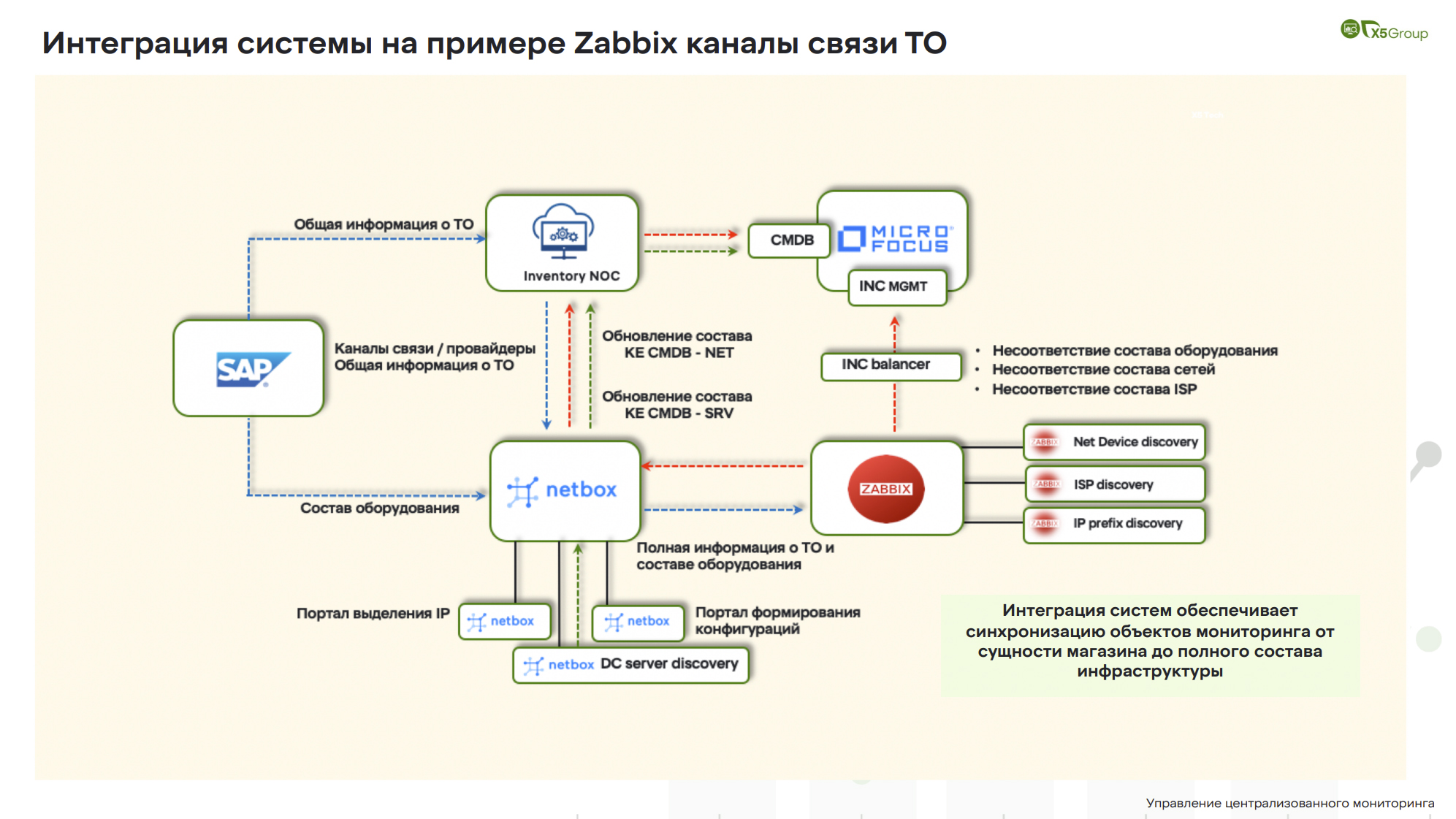
Представлена интеграция систем, на которой с одной стороны находятся бизнес-системы, в частности, SAP, а на другом полюсе находятся системы мониторинга.
Задача стояла в следующем: как сделать так, чтобы когда бизнес-подразделение открывает магазин, он практически мгновенно или в ближайшее время появлялся в наших системах мониторинга, и как сделать так, чтобы эти данные были обогащены всей необходимой информацией.
Когда объект создаётся в SAP’e, то общая информация (название магазина, дата открытия, контакты и т.д.) о нём уходит в наш Zabbix-портал. В конкретном примере это Zabbix-портал для подразделения сетевиков, отвечающих за коммуникацию с провайдерами и в целом за поддержание каналов связи.
Общие данные об объекте появляются в Zabbix-портале, но затем руками дополняются более детальной информацией. Это данные по каналам передачи данных, по скорости, контакты провайдера. Далее эта информация уходит в Netbox.
В момент добавления или актуализации информации, в Netbox из SAP’а приходит состав оборудования, бизнесовые инвентарные описи, проходит интеграция, Netbox наполняется информацией.
Что происходит в Netbox? В Netbox мы выделяем IP-адреса с помощью различного рода плагинов – Netbox хорошо кастомизируется, и уже в этот момент мы имеем весь необходимый объём информации для того, чтобы создать в мониторинге объект: адрес, канал связи, состав оборудования, IP-адреса, провайдеры. Происходит интеграция, причем она может происходить как туда, так и в обратную сторону. Если мы идем направо, в Zabbix, то мы создаем магазин. Если приходит информация, что магазин закрыт, объект снимается с мониторинга.
Но здесь происходит интересная вещь, которую делает Zabbix. Zabbix обвешан различного рода утилитами, назначение которых – проверить все ли правильно. Точно ли провайдер Ростелеком? Есть ли такие сети? Zabbix начинает свои проверки: он проверяет девайсы, которые стоят на месте, он проверяет провайдеров, проверяет IP-префиксы. Что-то он может исправить сам. По каким-то несовпадениям он создает заявки в нашей системе управления инцидентами, где уже службы поддержки или другие профильные подразделения занимаются разбором этих кейсов.
Что дает эта схема? Она обеспечивает максимальную синхронизацию объектов. В плане интеграции и работе с API Zabbix’а, то это, наверное, один из самых стабильных API-интерфейсов, с которыми мы работали. API Zabbix работает как часы: можно просто грузить огромные базы данных, но Zabbix будет обрабатывать огромные объемы информации.
Zabbix workview — панель сотрудника поддержки
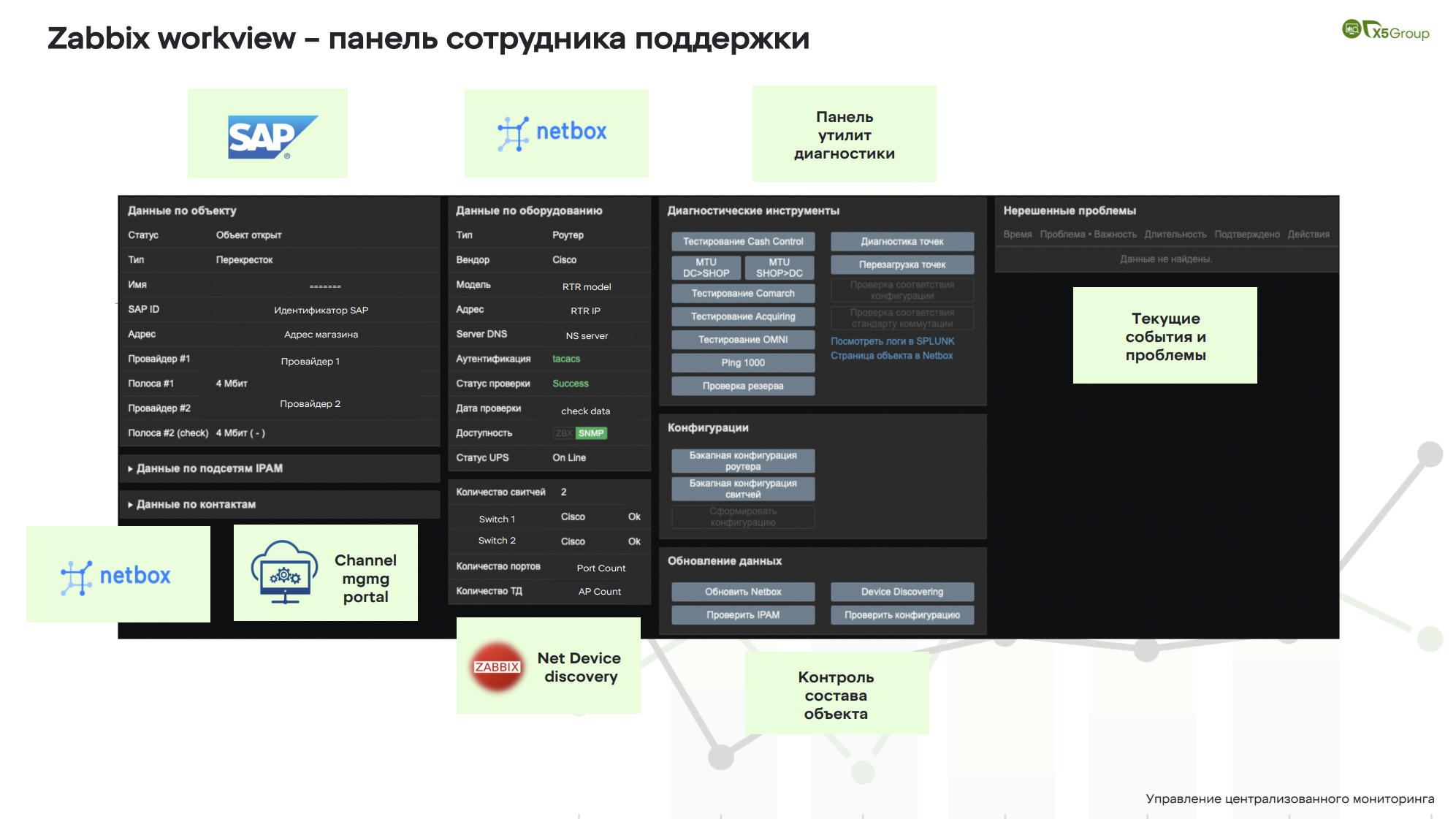 Окей, у нас есть синхронизация, что мы еще можем с этим сделать? Почему бы нам внутри Zabbix не наделать дополнительных кнопок, утилит, чтобы нам с этой информацией и со всей инфраструктурой внутри магазина можно было работать? Мы создали панель магазина, с которой работают сотрудники поддержки каналов связи и сетевой поддержки.
Окей, у нас есть синхронизация, что мы еще можем с этим сделать? Почему бы нам внутри Zabbix не наделать дополнительных кнопок, утилит, чтобы нам с этой информацией и со всей инфраструктурой внутри магазина можно было работать? Мы создали панель магазина, с которой работают сотрудники поддержки каналов связи и сетевой поддержки.
Здесь присутствует информация, которая приходит из бизнес-систем. Это магазин, это Перекресток, он открыт, у него есть адрес, у него есть канал связи, у него есть провайдеры. Из Netbox мы видим состав IP-сетей, но он здесь скрыт. Различного рода контакты – здесь указан наш Zabbix-портал. Также из Netbox мы видим, что там стоит маршрутизатор, это Cisco, у него есть IP-адрес, у него отлично работает аутентификация и какие-то протоколы.
По поводу системы бесперебойного питания, сам Zabbix конкретно эти данные не получает, это интеграция между Zabbix и инженерным подразделением. Сюда прилетает информация оттуда, то есть мы видим, что UPS(ИБП) тоже работает. По свитчам (switch) это уже то, что делает сам Zabbix, как он проверяет. То есть мы видим, что у нас два коммутатора Cisco, с ними все окей, количество свободных портов, количество доступа онлайн.
Панель утилит диагностики. Все кнопки в этой динамичной панели разрабатываются индивидуально по требованию заказчика. Здесь проводятся как самые простейшие проверки: PING, traceroute, MTU, так и диагностика, которая рассчитана на конкретную область инфраструктуры. Мы можем протестировать канал связи и точки доступа, можем их все перезагрузить в магазине.
Тестирование технологических сервисов. Здесь мы можем посмотреть конфигурации маршрутизаторов и свитчей, в том числе бекапные. Можем с помощью Zabbix управлять Netbox: если данные не совпадают, то в два клика информация будет синхронизирована в Netbox. Ну и нерешенные инциденты — у нас инцидентов не бывает, все магазины работают отлично.
Система динамического переключения каналов связи — централизованная
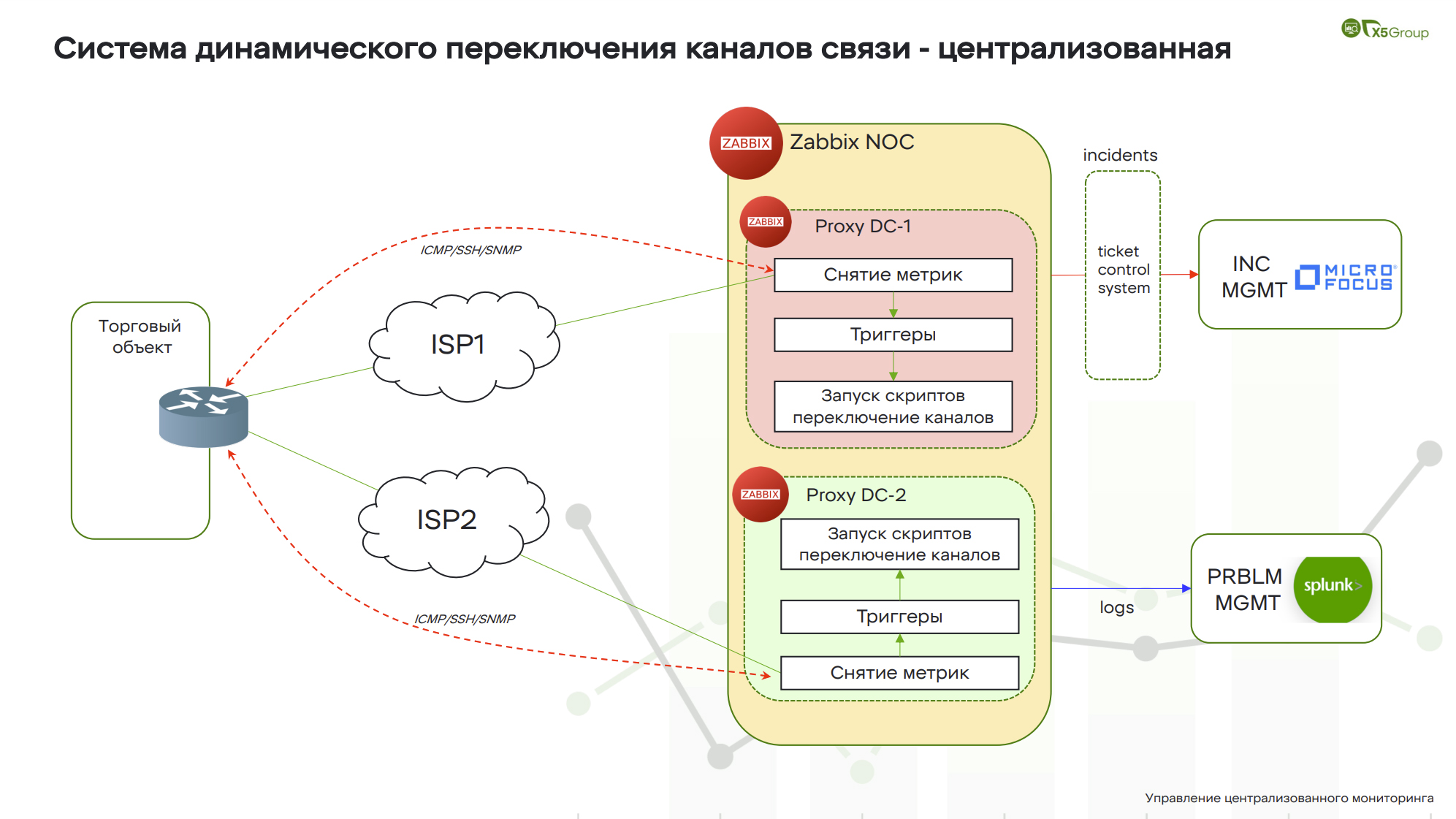
Это централизованная система динамического переключения каналов связи.
Какая идея? У нас есть магазин, в нем стоит маршрутизатор. В маршрутизатор подключены два канала связи. Оборудование не самое высокоинтеллектуальное, сами понимаете. Единственный способ определить, что канал не работает, — либо полное падение физического линка, либо падение протокола маршрутизации. Мы никак не можем реагировать на такие кейсы, когда у нас просадка по задержкам, проседает джиттер, либо на канале потери.
Какая может быть ситуация? Канал работает плохо. По целевым показаниям мониторинга канал поднят, всё окей. Соответственно, сотрудники магазина должны создавать заявки.
Какая идея? С помощью нескольких Zabbix Proxy мы организовываем асинхронный мониторинг этих каналов. Мы можем формировать достаточно сложные триггеры, например, если в течение 20 минут у нас четыре раза наблюдается просадка по задержкам, то канал переключается. Соответственно, на этих Proxy располагается набор скриптов и утилит, которые подключаются к оборудованию, эмулируя таким образом работу инженера, и переключают канал. Когда качество основного канала восстанавливается, система сама переключается обратно. Это не всё.
По событию Zabbix может создавать и управлять инцидентами по объекту. Причем он может как создавать инциденты, так и проверять статус инцидента в ITSM-системе и даже закрывать их. Но и это еще не все. Когда система переключает канал связи, внутри включается ее встроенный механизм логирования, который показывает нам, какой это магазин, какой это был оператор, как часто переключался канал. Соответственно, мы все эти логи отправляем в наш Splunk, где начинаем работать с этими данными.
Собирая такую большую статистику по таким переключениям, мы можем стартовать процесс problem management. Ведь мы можем понять, какой магазин работал хуже всего, допустим, какой провайдер самый аварийный, где мы можем приложить усилия для того, чтобы повысить качество сервиса.
Система динамического переключения каналов связи — децентрализованная
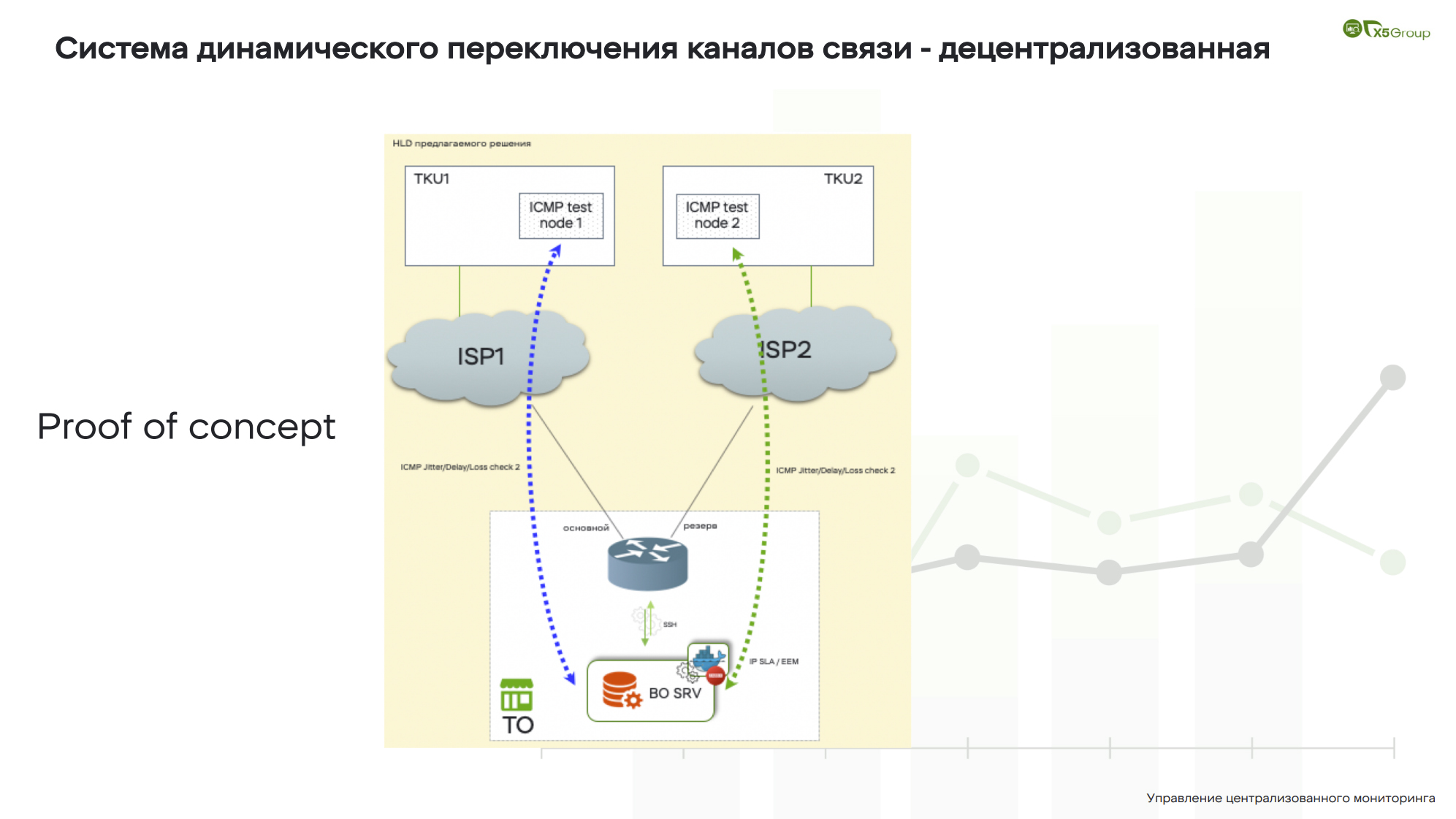 Ну, и последний наш слайд, он, в общем-то, похож на предыдущий, но здесь мы говорим немного о другом. Что, если мы не можем переключать каналы из центра? Что, если нам нужно тестировать качество связи прямо из магазина? Как нам сделать свой аналог CISCO IP SLA, такой же интеллектуальный, со всеми проверками, и чтобы это было аналогично тому, что мы сделали на предыдущем слайде?
Ну, и последний наш слайд, он, в общем-то, похож на предыдущий, но здесь мы говорим немного о другом. Что, если мы не можем переключать каналы из центра? Что, если нам нужно тестировать качество связи прямо из магазина? Как нам сделать свой аналог CISCO IP SLA, такой же интеллектуальный, со всеми проверками, и чтобы это было аналогично тому, что мы сделали на предыдущем слайде?
Гениальная идея. Давайте возьмем маленький Zabbix, все это портируем, скомпилируем образ и распространим в Docker Engine, чтобы он начал делать свои проверки. Решение нужно было сделать очень быстро, и оно отработало. Система функционировала отлично.
Что в итоге? Zabbix это система, которую поставил и забыл, она идеально подходит на такую автономную работу. У Zabbix отличный API, то есть, если мы говорим об управлении нодами откуда-то из центра, то у нас есть полный функционал. Zabbix отлично интегрируется с различными базами данных, даже с теми, которые можно не разворачивать как отдельный контейнер: все может быть внутри, оно будет работать отлично. Мы сделали такую штуку, она действительно работает и мы прорабатываем дальше решение, как нам дальше с этим жить.
Закончить хотелось бы сказав следующее: прикладывая немного воображения и используя Open Source утилиты, можно создавать интересные решения, которые предоставляют высокую ценность.