Как телекоммуникационная компания “BT Group” использует Amazon CloudWatch для мониторинга миллионов устройств
Британская телекоммуникационная компания “BT Group” создала с помощью Amazon Web Services интересное решение для мониторинга. Для сбора и анализа телеметрических данных с миллионов устройств используются следующие инструменты:
- дашборды Amazon CloudWatch;
- “аварии со сложным условием” (composite alarms — такой сигнал об аварии будет подан только в том случае, если в аварийное состояние перейдет несколько определенных вами объектов);
- свой формат данных EMF (спецификация JSON).
Внедрение мониторинга осложняется высокой кардинальностью данных (high-cardinality, такими данными являются, например, ID, телефонные номера и т.д.), которые нужно собирать и анализировать. Мониторинг данных с высокой кардинальностью сопряжен как с финансовыми затратами, так и с напряженной умственной работой. Постоянно возникает вопрос: “Как отслеживать и анализировать эти данные с максимальной эффективностью?”. Ответ на него был найден специалистами из “BT Group” и Amazon CloudWatch. Изучим подробнее их опыт.
Обзор
Изначально задачей компании был сбор данных с более чем миллиона устройств Smart Hub 2, с помощью которых жители Великобритании получают широкополосный доступ с Интернет, Wi-Fi и связь DECT (Digital Enhanced Cordless Telecommunications). В таком случае ключевыми показателями являются: задержка (“latency”), джиттер (“jitter”), потеря пакетов (“packet loss”) и неудачные вызовы (“failed calls”).
Для команды “ВТ” было важно агрегировать данные по разным “измерениям”, чтобы лучше понимать генерируемые события (см. Рисунок 1). Такой подход позволяет эффективнее анализировать данные на разных уровнях и тщательно контролировать расходы. Группирование данных также происходит по типу вызова (экстренные, мобильные, международные, локальные, входящие и исходящие) и по причине завершения в соответствии со спецификацией TR-069 (техническая спецификация, описывающая протокол управления абонентским оборудованием через глобальную сеть CWMP). Благодаря подобной организационной структуре удается поддерживать баланс между наблюдением подробной телеметрии по каждому устройству и мониторингом ситуации и системы в целом.
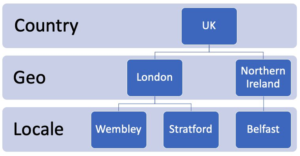
Рисунок 1. Три уровня агрегации, используемые при мониторинге качества звонков клиентов
Использование разных типов телеметрических данных (метрик и логов) обеспечивает получение экономически оптимального и эффективного решения. Логи используются для хранения телеметрии по устройствам, метрики — для трех уровней агрегации.
Подход
Детализация информации на уровне устройства необходима для устранения возможных неполадок у конкретного клиента. Агрегированные данные (то есть абстрактно представленные на более высоком уровне) позволяют предотвращать массовые сбои. Обеспечить такой подход способен особый формат данных — CloudWatch EMF.
EMF извлекает данные метрик из логов, что помогает сэкономить деньги и усилия. Команде остается настроить визуализацию и определить условия аварий на основе ключевых показателей качества звонка.
Ниже приведен пример конфигурации EMF, в которой сохраняются события callSuccess и callFailure как сгруппированные по регионам метрики CloudWatch. Индивидуальные данные телеметрии по каждому устройству представляются в виде логов в CloudWatch Logs.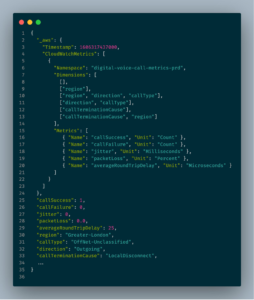
Рисунок 2: Конфигурация EMF для собранных показателей и связанных регионов
Соответственно, сначала данные будут получены в виде лога. Затем они преобразуются в метрику — агрегированную точку данных. Сохранение логов по каждому устройству дает дополнительные данные о качестве звонков и позволяет глубоко изучать возникающие проблемы и неполадки. Это реализуется с помощью инструмента CloudWatch Logs Insights.
Другой инструмент, который активно используют инженеры “BT”, — аварии со сложным условием (“composite alarms”). Аварии со сложным условием коррелируют с уровнями агрегации, о которых говорилось выше. Например, если авария появляется на самом низком уровне агрегации, то на самом высоком уровне она отобразится лишь как предупреждение. Но если сработает несколько сигналов об авариях на нижних уровнях, на высоком это уже будет выглядеть как критическое событие.
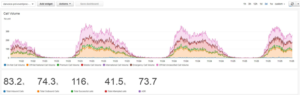
Рисунок 3: Количество звонков с callType в виде серии

Рисунок 4: Количество завершений вызова с callTerminationCause в виде серии
Заключение
Созданное с помощью сервиса CloudWatch решение позволяет “ВТ” контролировать миллионы устройств Smart Hub 2 по всей Великобритании. Особый формат данных EMF и отслеживание аварий со сложным условием дают возможность выстроить иерархию с разными уровнями абстракции. Для решения проблем каждого отдельного клиента используются логи, а извлеченные из них метрики показывают общую картину (на уровне областей, регионов, целой страны).
Киаран Кирни, дата-инженер из “ВТ”, говорит следующее: “В течение первых двух недель с момента, как мы запустили решение, операционным группам удалось быстро предотвратить серьезный сбой. Предыдущие системы потратили бы гораздо большее время на поиск уязвимостей. Теперь мы быстрее реагируем и быстрее приводим все в порядок”.
Особое преимущество созданной системы заключается в возможности ее масштабировать. В планах компании внедрить ее в другие проекты, что позволит улучшить обслуживание более 30 миллионов клиентов.