Как вовремя разбудить дежурного админа? Мониторинг облака Selectel
Александр Барсков [Selectel]
Расшифровка видео с доклада на Big Monitoring Meetup 9, состоявшегося в Санкт-Петербурге, все мероприятия сообщества Monhouse:
Меня зовут Александр Барсков, я системный администратор дежурной службы облака в компании «Selectel».
Сегодня я расскажу, как мы в дежурной службе обрабатываем алерты, как мы решаем проблемы мониторинга, и о том, как мы ходили на рынок за инцидент-менеджментом. Также разберемся со сложностями перехода на Open Source и интеграцией Grafana OnCall OSS.
Коротко о Selectel:
- более 40 продуктовых решений;
- 6 собственных дата центров;
- более 800 сотрудников;
- около 23000 клиентов.
С 2008 года мы помогаем решить клиентам бизнес-задачи разной сложности, поддерживаем инфраструктуру, помогаем строить нечто новое и сами открываемся новому.
Нашему облаку 10 лет, за это время мы открыли 13 пулов, накопили 75000 виртуальных машин. В среднем имеем 10 критичных алертов в день.
Расскажу как мы в Дежурной службе Облака Selectel справляемся с сотнями алертов в сутки: -проблемы в работе с мониторингом и их решения; -автоматизация процесса доставки уведомления дежурному; -наш опыт работы с проприетарными системами управления инцидентами; -конкретный кейс переезда на Grafana Oncall OSS; -сложности перехода на Open Source
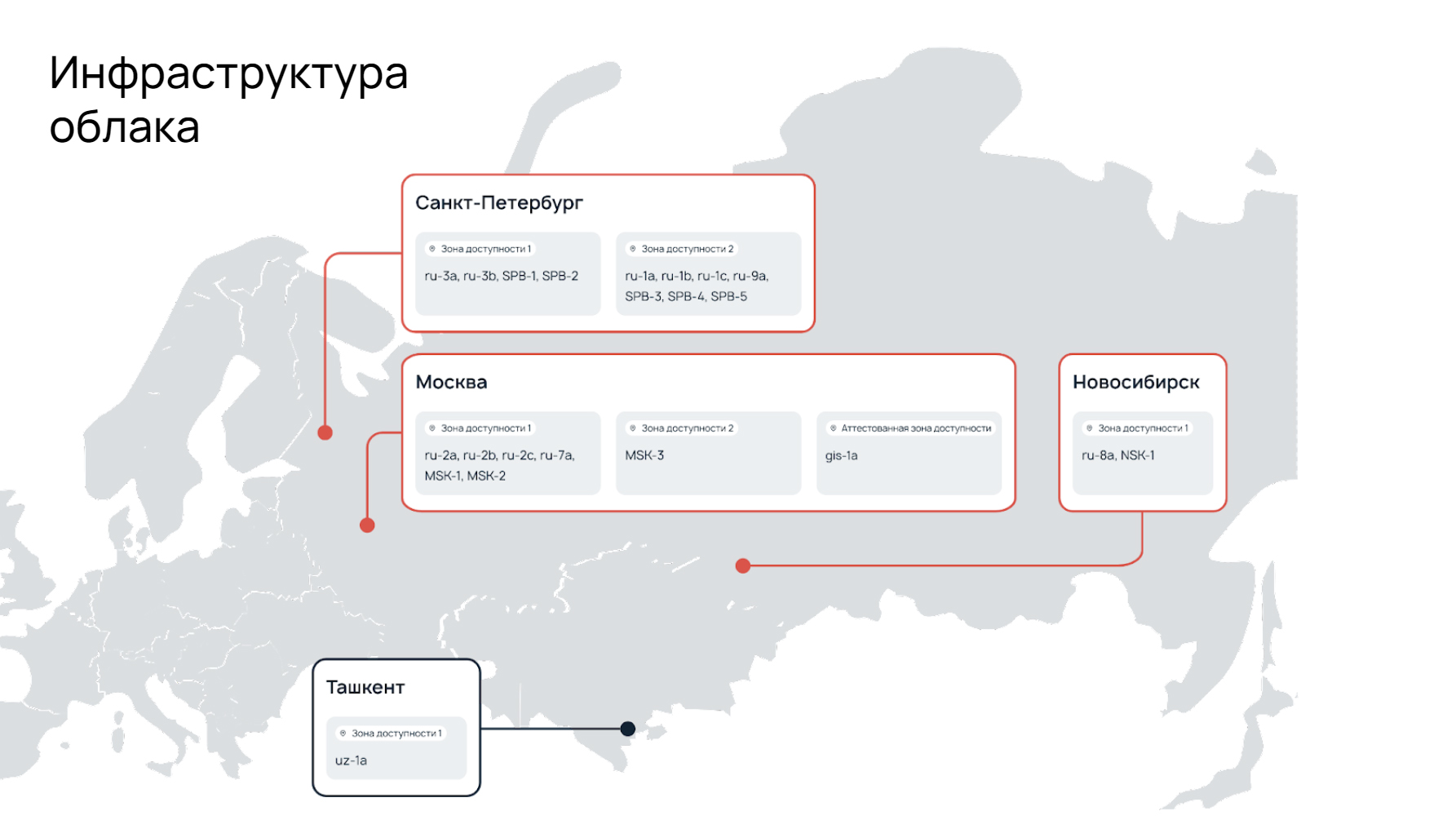
Выше представлена наша инфраструктура. То, что находится под названиями -ru, gis, uz + код — облако, SPB, MSK, NSK — это уже выделенные серверы, co-location, кастомы и т.д.
Все наши дата-центры связаны между собой по сети, находятся в Петербурге, Москве, Новосибирске и Ташкенте.
Разработка и поддержка
Как у нас происходит общение с клиентом? Клиент взаимодействует с нами через API, многоуровневую тех. поддержку и с помощью инструментов панели управления.
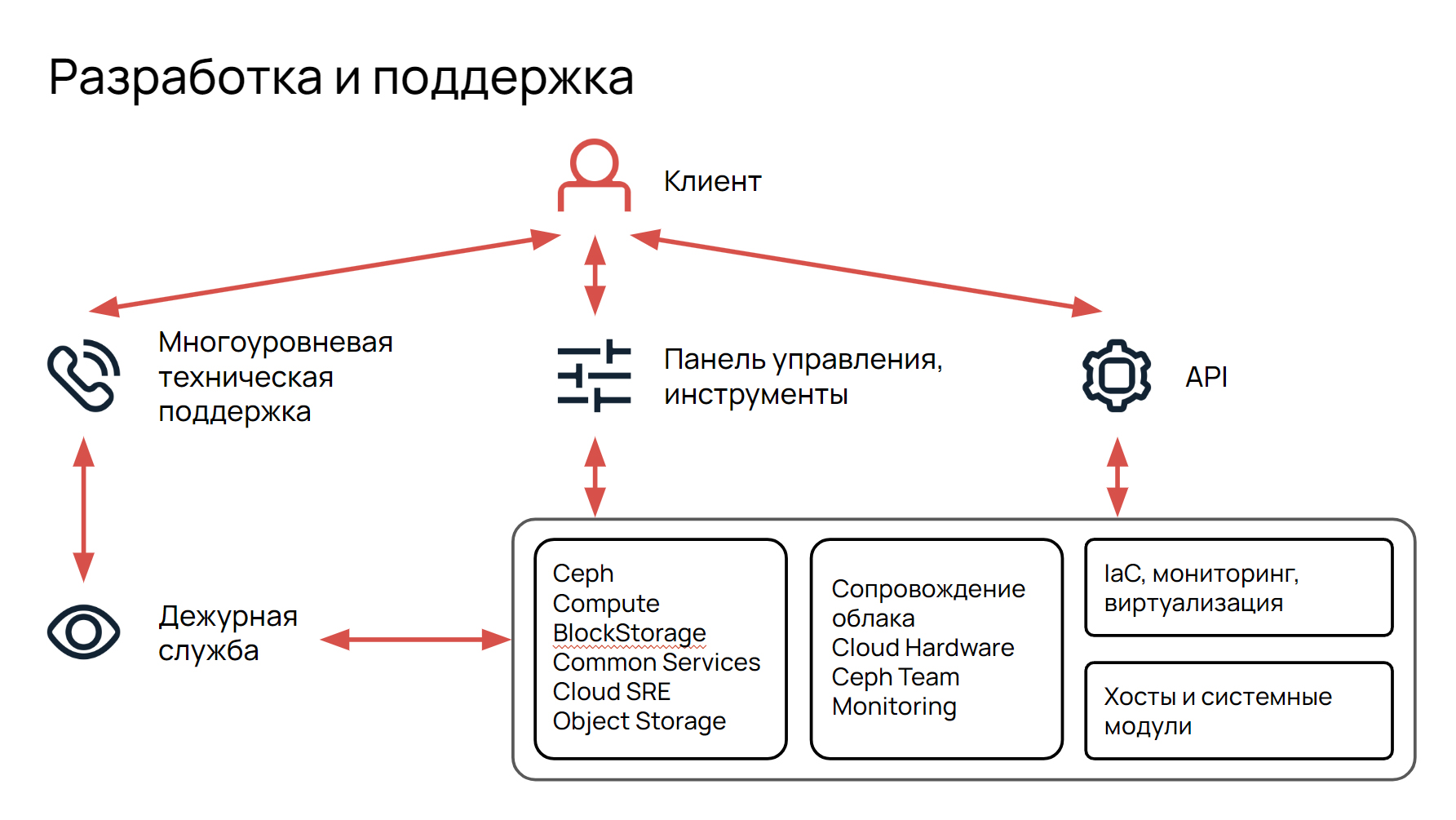
У нас 2 линии технической поддержки, поддерживающие клиентскую инфраструктуру 24/7, 365 дней в году.
Есть задачи, c которыми техническая поддержка не может помочь, тогда включается дежурная служба. Мы имеем прямой доступ ко всем компонентам, помогаем решать технические трудности. Получается, что мы — некая помощь и саппорту, и клиенту.
Наш дежурный отдел работает с сообщениями мониторинга. Мы следим за большой инфраструктурой: более 1500 постоянно работающих физических серверов. Мы разбираемся с инцидентами и устраняем аварии, помогаем саппорту со всеми проблемами, с которыми к нему приходят клиенты по поводу облаков. Вот так раньше выглядел наш мониторинг, его концепция и схема работы:
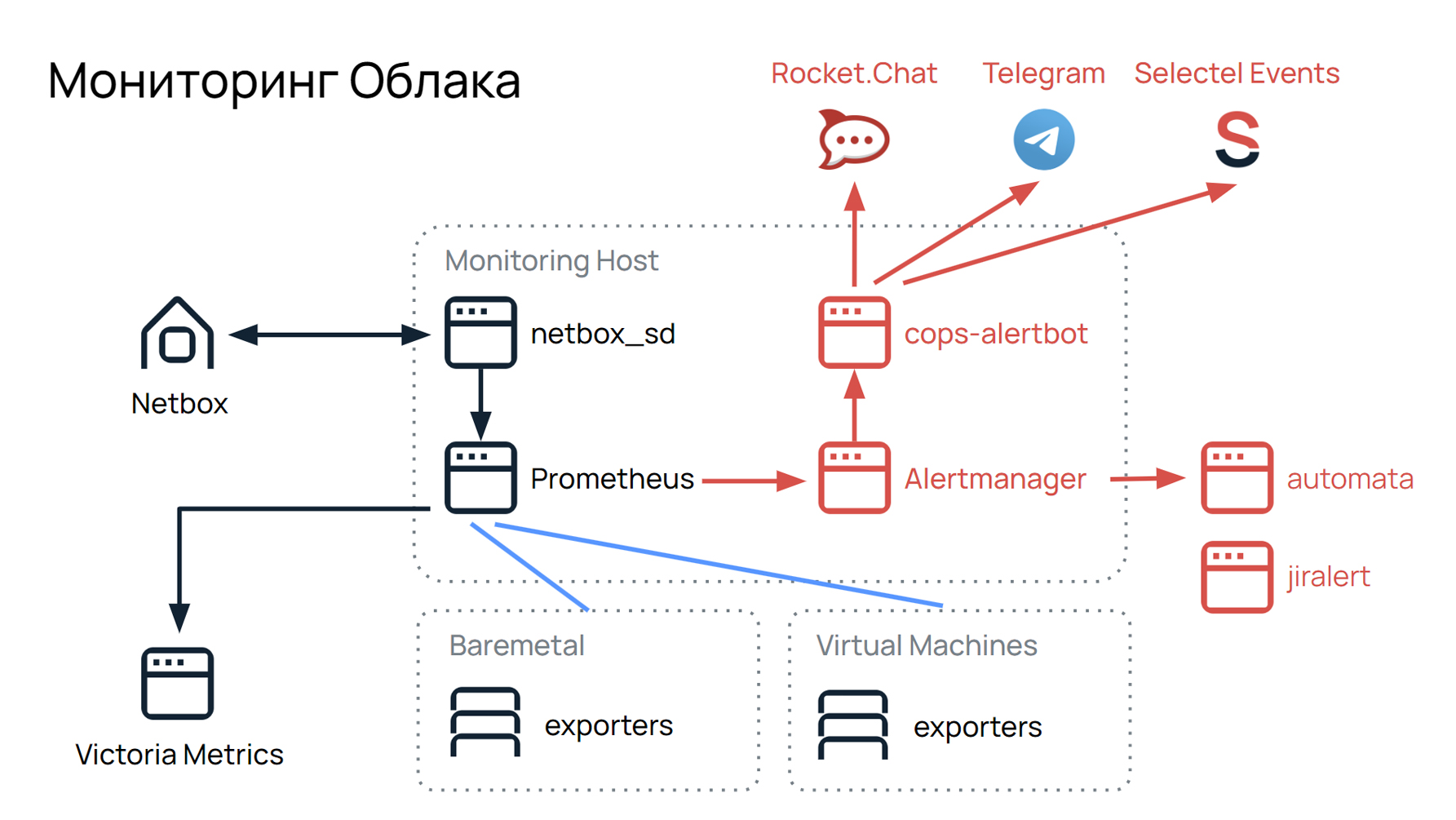
У нас есть серверы, Bare Metal-железки, виртуальные машины, и на каждые из них есть экспортеры. Prometheus собирает данные с этих экспортеров, по определенным лейблам и группам отдает в Alert Manager. Alert Manager по своим правилам группирует их и через COPS Alert BOT передает в три наших мессенджера: Rocket Chat, Telegram и Selectel Events. От последнего мы уже отошли, так как сейчас в нем нет особого смысла, но об этом позже.
Prometheus хранит данные Victoria Metrics до полугода, информацию о серверах можно посмотреть в Netbox. Это инструмент, который предоставляет информацию о расположении серверов, в стойках, в датацентрах, их статусах, местах подключения. Передается это все через плагин Netbox SD.
Также у нас есть автоматизация рассылки алертов через Automata и Jira Alert. Jira Alert это интеграция с Jira. То, что из Alert Manager идет в Jira Alert, автоматически создает задачу в Jira.
Требования к системе мониторинга
Когда мы смотрели на это все и продумывали, как нам изначально устроить мониторинг, мы решили для себя выделить несколько важных требований.
- Скорость доставки уведомлений. Нам очень важно, чтобы все уведомления приходили не через полчаса после аварии, а как можно скорее.
- Читаемые сообщения в удобном формате. Потому что, когда спишь ночью, внезапно просыпаешься и видишь, что сломался сервер R2-D2-50001337, хочется, чтобы было сразу понятно, куда идти и кому помогать.
- Инструкция и документация. Каждый алерт для некоторых сотрудников бывает новый, непредсказуемый. Есть алерты, по которым нужна четкая инструкция, как поступить, какую команду ввести, чтобы, например, не разрушить кластер MySQL.
- Агрегация уведомлений в очереди. Не очень приятно, когда по одному сервису валятся 20 серверов, и потом выходит так, что у пользователя скапливается куча отдельных сообщений в телеграмме, в Rocket-чате или где-то еще. Хотелось бы, чтобы они группировались.
- Связи между зависимыми сервисами. Важно, чтобы была видна сама суть того, что значит этот алерт — причина какого-то действия, каких-то работ или уже следствие каких-то аварий.
- Сбор данных для анализа. Он необходим, чтобы понимать все детально. Возможно, в этом месте у нас было больше проблем вот с этим компонентом, возможно, его нужно доработать, возможно, обращались клиенты по таким-то причинам, и можно как-то улучшить и работу с этим алертом и сервис в целом.
Пример того, как это выглядит смотрите ниже:
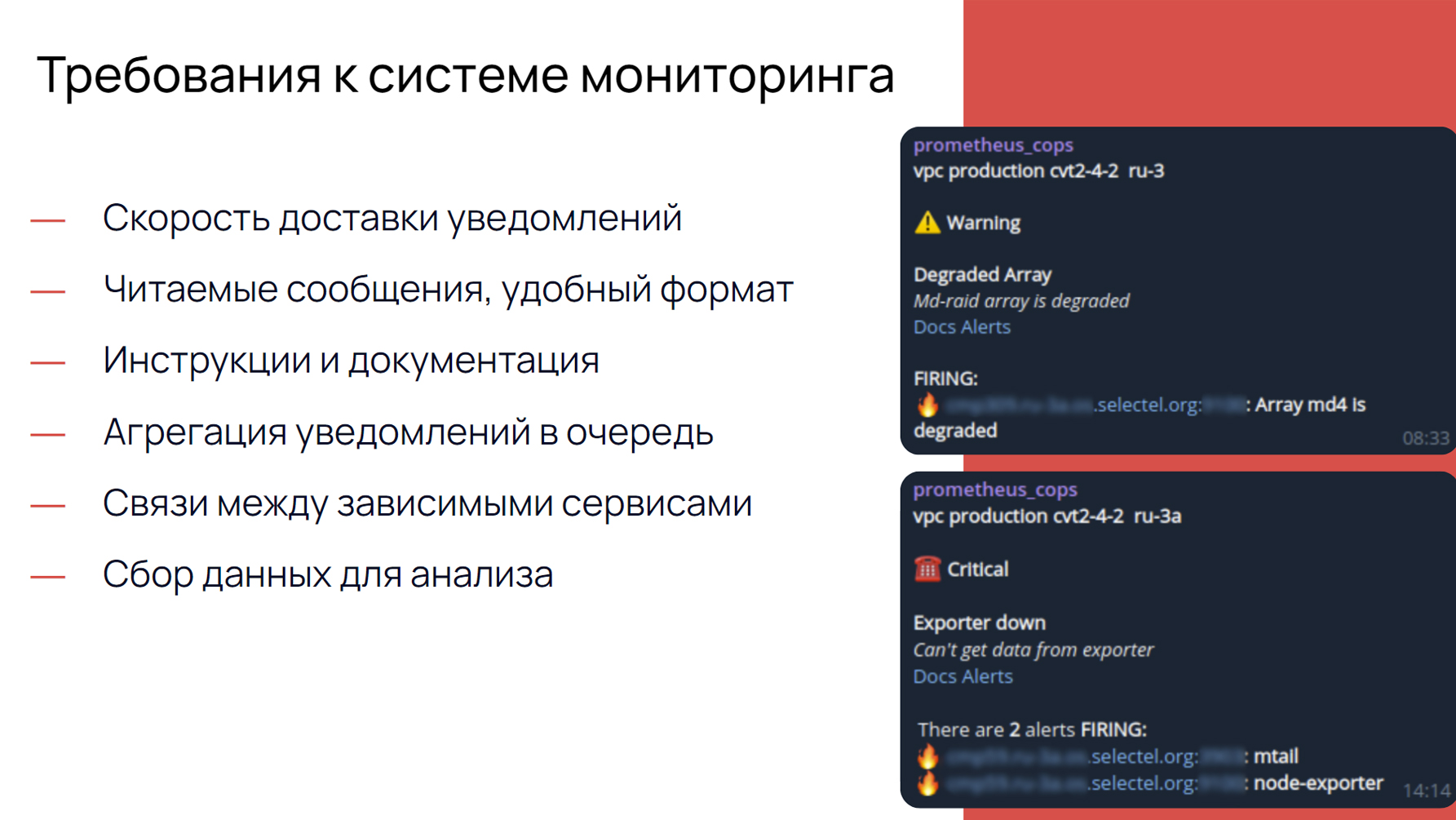
В сообщениях есть:
- название сервиса/сервера;
- статус алерта;
- название инцидента;
- описание инцидента;
- ссылка на документацию;
- на каком сервере проблема;
- какие сервисы не работают.
Сразу становится ясно, что случилось: в первом случае деградировал массив, во втором случае упал экспортер. Также мы видим ссылки на документы и инструкции, как этот алерт обрабатывать.
Такая схема нам помогала, но была не идеальна. У нас был мониторинг, из которого валились сообщения во все мессенджеры, и был саппорт, который сидел на линии круглые сутки. Помимо того, что саппорт следил за облачной инфраструктурой, он также следил за инфраструктурой выделенных серверов, помогал клиентам консультациями, и отвечал на звонки.
Все постоянно сидели на звонках, и не всегда получалось вовремя на них отвечать, или звонили не тому админу. Вместе с этим мы и саппорт не видели, что связей между алертами разных серверов тоже нет. Мы хотели, чтобы сотрудникам стало легче: убрать бесконечные окна, интерфейсы, чаты. Хотелось, чтобы это все было упорядочено.
Сложно было понять кто занимается алертом и занимались ли. Может он сам отрезолвился, человек проспал, а проблема осталась до утра. Нет истории обработки алерта: звонили или не дозвонились, кто ответственный, предпринимались какие-то действия или нет, создана ли задача. Как следствие, нет данных для анализа. Для бизнеса время реакции очень важно, но учитывая все вышеописанные факторы, у нас оно могло достигнуть критического значения прежде, чем с проблемами разберутся.
Появилось желание решить эти вопросы раз и навсегда, составили план и поставили ключевую задачу — улучшить сервис поддержки, проработав все минусы, либо вовсе их устранив.
- Ускорить время реакции на инциденты. Нам хотелось, чтобы звонки поступали не спустя полчаса с момента падения, а сразу, как только что-то пошло не так.
- Автоматизировать звонок дежурному. Это нужно, чтобы снять нагрузку на поддержку и исключить человеческий фактор.
- Выделить единое окно, очередь алертов.
- Наладить workflow и исключить тысячу чатов у нас и у саппорта, так как все сразу мониторить сложно. Хотелось сделать так, чтобы алерт появился в три часа ночи, его взял ответственный. Он оставил комментарии, что все решается планово или сразу оставлял ссылку на задачу. И уже потом оставил на утро либо отложил.
- Прояснить взаимосвязь между сервисами, чтобы было понятнее, где причина, почему этот алерт возник, возможно, как следствие каких-нибудь плановых работ, внепланового отключения коммутатора или чего-то еще.
- Собирать данные для анализа и прогноза. Возможно, в будущем, если мы починим сервис, который за него отвечает, то будет меньше обращений и меньше алертов на данную тему.
Поиск решений
Мы пошли на Open Source рынок. Посмотрели — сыровато. Требовался достаточно большой объем работ, пришлось бы даже нанимать отдельную команду разработчиков, чтоб прикрутить все необходимое. Мы изучили Dispatch от Netflix и Oncall от LinkedIn. Dispatch оказался неплохой, но все еще достаточно сыроват: похоже на единое окно, но остальным требованиям он не отвечал. OnCall от LinkledIn мы даже не смогли нормально прикрутить. Он нам не поддался от слова совсем.
Еще раз изучив рынок Open Source, мы подумали, что можно обратиться и к проприетарным коммерческим решениям, там было все готово — мы получали широкий набор инструментов с быстрым запуском.
- Opsgenie от Atlassian — хороший инструмент в плане интеграции, в плане работы с ним, в плане тестирования. У него была своя интеграция с Jira — это и плюс и минус, потому что у нас уже стояла своя интеграция, и переписывать ее ради Opsgenie нам не хотелось.
- Datadog — непростой инструмент, который важно грамотно подготовить. У нас с ним справиться не получилось.
- Amixr— отечественный ChatOps на базе Slack и Telegram. Регистрация для новых пользователей закрыта, но сервис все равно не подходит, так как нет поддержки звонков на мобильные.
- VictorOPS / Splunk On-Call — официально в стране не продается.
- PagerDuty — дорогой, но очень качественный и хороший вариант. Он завелся прямо сразу у нас из коробки. Звонки есть, расписание есть, единое окно есть, все остальное есть. Даже дошло до того, что он озвучивал нам алерт: когда ты берешь трубку, робот сообщает, что именно, какой сервис, на каком сервере пострадал, и это было очень удобно и славно.
В тот момент наша инфраструктура алертинга выглядела следующим образом:
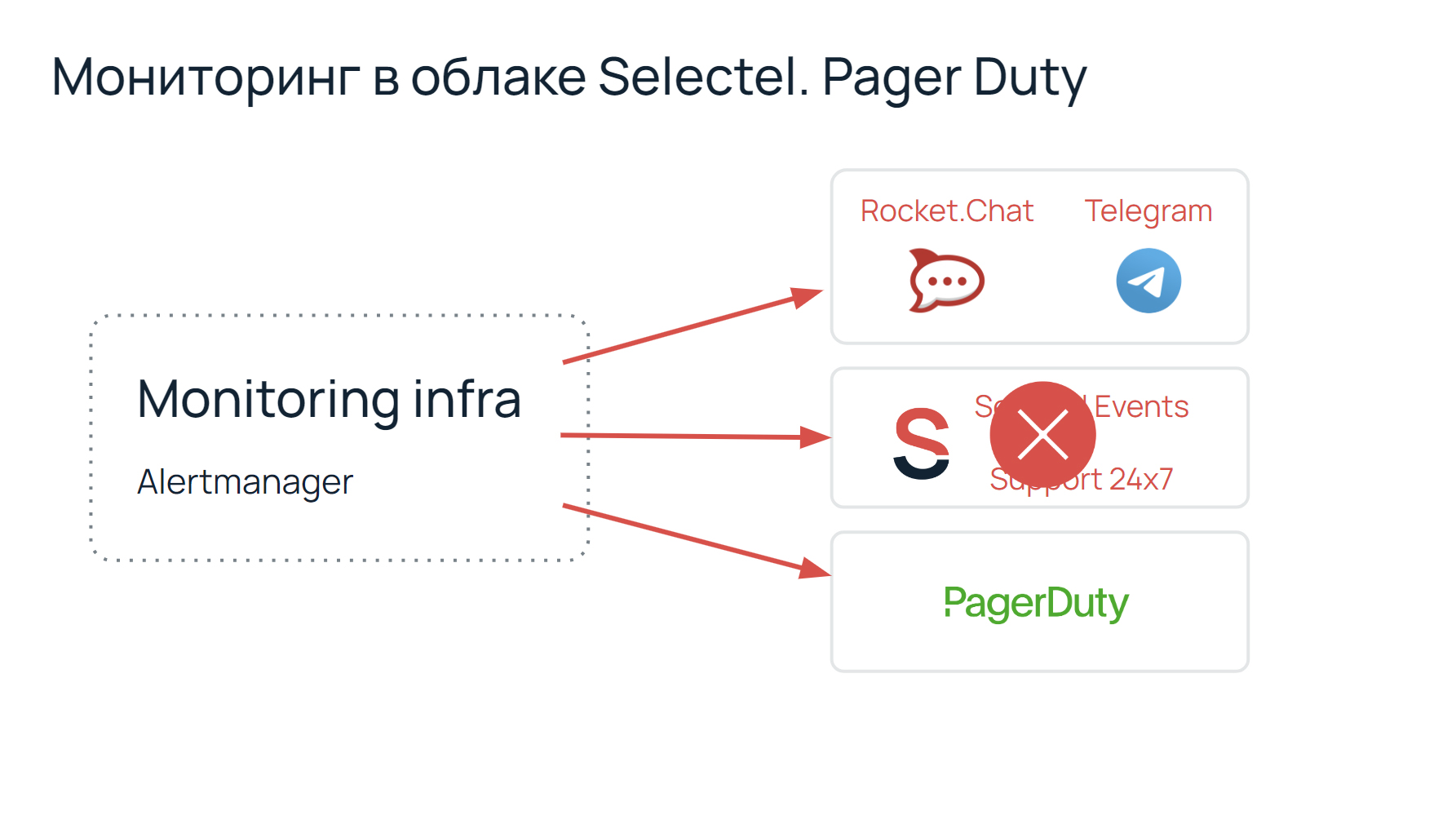
Мы исключили человеческий фактор в виде саппорта и сняли нагрузку с людей, за что они нам сказали большое спасибо. Так мы перешли на PagerDuty.
Но в феврале 2022 года PagerDuty перестал сотрудничать с российскими компаниями. Мы были немного в панике, потому что только привыкли к удобству, а у нас уже все отбирают. К тому же, не очень-то хотелось возвращать нагрузку на саппорт, все обратно перестраивать, переходить на старые рельсы.
Еще раз прошерстили рынок и нашли его — GoAlert.
Этот инструмент имел достаточно минимальный набор функций. Мы его развернули, написали прослойку между GoAlert и API сервиса телефонии zvonok.com, получили автоматический дозвон дежурному. Также там были графики и единое окно алертов.
Но у нас еще остался список незакрытых проблем:
- не хватало прозрачного потока работы;
- не было истории и комментариев;
- не собирались данные для анализа;
- график дежурств не позволял вносить изменения текущих дежурств.
GoAlert был больше похож на уведомлялку, поэтому мы отказались и от GoAlert и перешли на Grafana On-Call, релиз которой состоялся осенью. Мы развернули ее для тестов, нам понравилось. Мы переписали сервис API-телефонии под zvonok.com. Изначально в OnCall использовалось Twilio, но так как мы опасались новых проблем с зарубежными сервисами, мы решили, что лучше будем пользоваться отечественными решениями.
Добавили синхронизацию контактов сотрудников. У нас есть внутренний портал, на котором есть вся информация о сотрудниках — мы добавили интеграции с ним и в январе перешли на него полностью. Наш мониторинг стал выглядеть вот так:
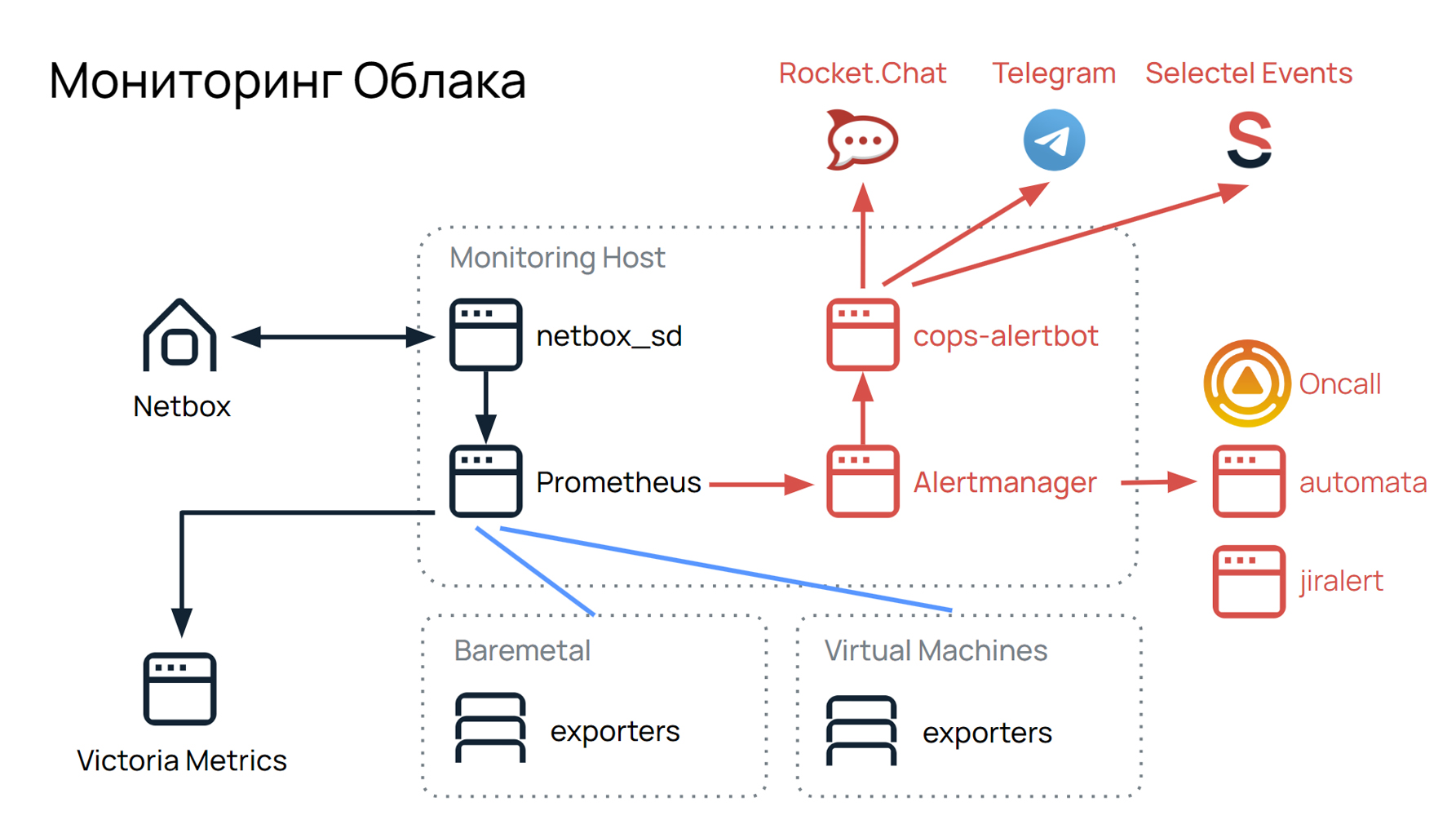
Здесь появился OnCall, все остальное почти неизменно, оставили только Telegram, остальные мессенджеры уже почти не используем.
Если посмотреть слева-направо, то видно, что тут есть инфра-мониторинг — это любое средство, любой компонент, любой сервис, который поможет вам с мониторингом, то есть Аlert Manager, Grafana Alert, Zabbix. Вы можете выбрать любой, и он прикрутится и развернется из коробки очень быстро. На тот момент мы работали с Alert Manager, и получалось, что данные оттуда шли в backend, который у нас был в двух экземплярах.
Backend развернут в Kubernetes и при падении одного из экземпляров все переключается на второй. Все зарезервировано — есть интеграция с нашим порталом, на котором есть Redis, RabbitMQ, Engine. Также у нас прикрутилась база данных Postgres в двух экземплярах, которую тоже развернули через Kubernetes. Так получается, что из backend идут запросы в API телефонии zvonok.com, и он уже звонит дежурному администратору. Здесь можно прикрутить что угодно — Telegram или что-то еще, в Grafana OnCall это доступно.
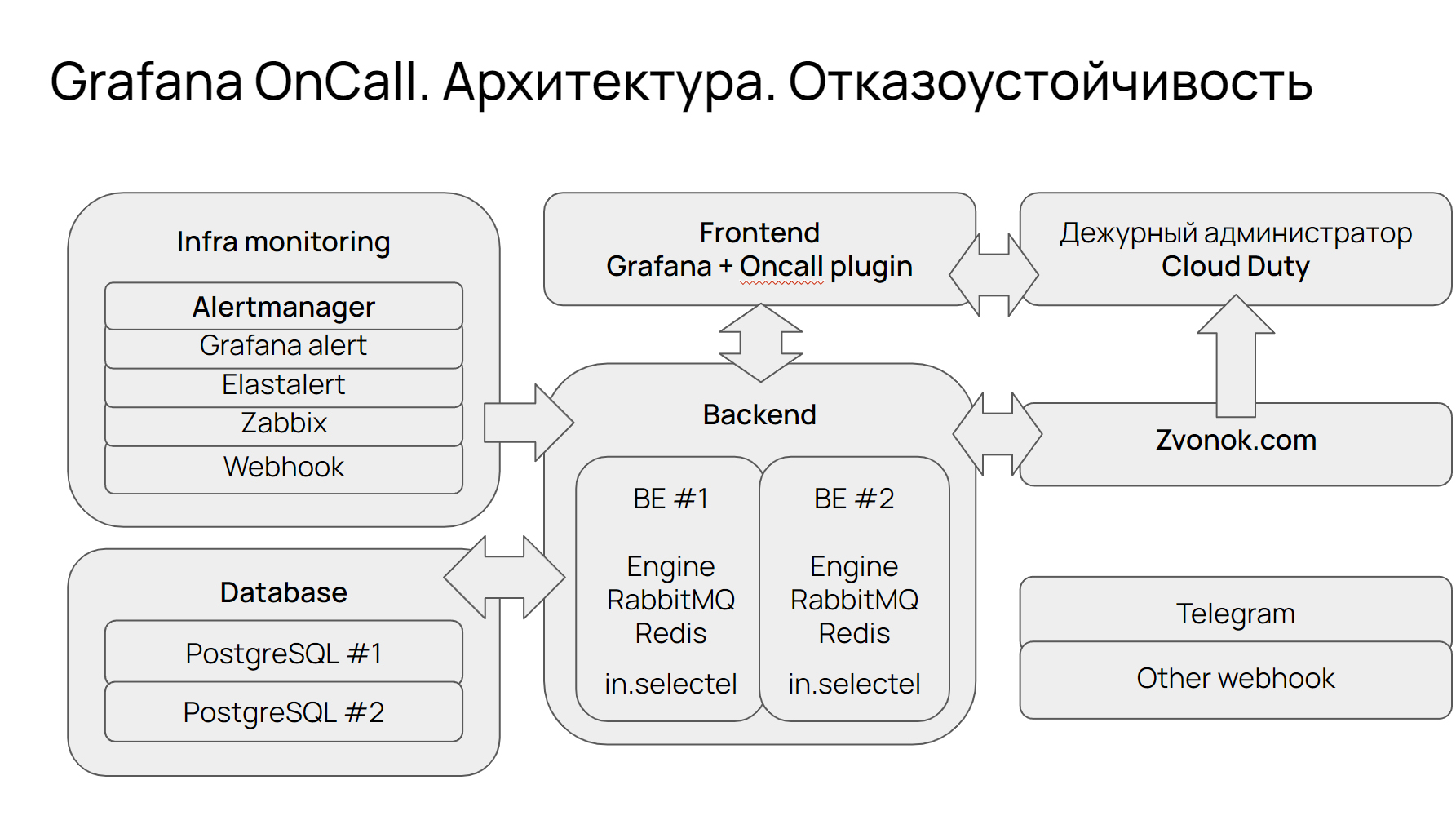
Мы поняли, что это наш идеальный вариант. Как минимум, у Grafana OnCall есть коммерческая поддержка — это значит и бесплатные сервисы будут дополняться, апгрейдиться, будут допиливаться новые фичи. Также есть готовый механизм для надежного запуска в Kubernetes, что немаловажно, чтобы быстро и качественно развернуть инфраструктуру. Есть интеграция из коробки с Alert Manager, Zabbix, и Grafana — вы просто прикручиваете, что хотите.
Также нас очень подкупило то, что это отечественные разработчики, создавшие Amixer, с ними было приятно общаться. Еще мы доделали сами и расширили инцидент-API, добавили юзер WEB-hook, интегрировали с внутренним порталом.
Итоги
На данный момент мы имеем всего лишь две минуты на оповещение о критическом алерте, мы сняли нагрузку с поддержки, за что и они нам благодарны, получили единое окно, в котором видно все алерты, их статусы и ответственных, видно, когда был создан алерт, историю. Поток задач стал абсолютно прозрачным, структурированным и контролируемым. Расписание дежурств удобнее по сравнению с GoAlert, создается на бесконечный цикл. Ты заносишь четырех человек, и они по бесконечности ротируются сколько угодно. Если нужно внести изменения, то просто вносишь отдельного сотрудника, как override. Мы получили базу событий для последующей аналитики.
Что мы хотели? Реализовать взаимосвязи между сервисами и алертами. Это все еще реализовано не до конца — пока что видно только то, что прилетел алерт, и мы по названию того или иного сервиса определяем причины и связи. А еще в будущем хотим сделать более качественную визуализацию: графики, тренды, показатели, графически приятно отображающиеся внутри.
Мы помним и о нашей работе с PagerDuty, теперь хотим добавить озвучку алерта во время звонка дежурному, ну и какой-то некий ChatOps в телеграмме.
Так мы переработали свой регламент работы с алертами и авариями. Хотели получить понятные и простые сообщения от мониторинга, инструкции в алертах, автоматический звонок на мобильный, очередь алертов и единое окно, взаимосвязь, которая еще в процессе, и сбор данных. Мы это все получили и мы рады.