Работа с мониторингом облака Selectel. Регламенты и процессы (Александр Бондарев, Selectel).
Сегодня мы с вами поговорим о том, как компания Selectel работает с мониторингом. Поделюсь опытом, покажу наши кейсы, а также попрошу вас поучаствовать в этом. Я не зря вышел сюда с нашим талисманом — Ти-Рексом. У меня их три штуки, одного я отдам за лучший вопрос, два других отдам самым активным участникам.
Пожалуй, начнем. Наверное, стоит пояснить, почему я здесь. Последние 3 года я работал в хостинге, руководил службой технической поддержки и, собственно, большей частью занимался именно процессами. Последние полгода после технической поддержки я работаю в Selectel и руковожу группой дежурной службы. Доклад будет совсем не технический, скорее про людей, про работу с ними. Интересно будет менеджерам, ведущим специалистам, которые занимаются настройкой процессов, но не технарям, извините.
Расскажу о взаимодействии непосредственно с мониторингом, о том, как мы с ним работаем, как он у нас настроен, в каком виде он используется; расскажу, как мы реагируем на инциденты, устраняем аварии, работаем с нештатными ситуациями. Также познакомлю вас с нашим опытом обучения на ошибках.
В двух словах расскажу про Selectel. Это довольно большая компания, которая занимается предоставлением услуг облачной инфраструктуры и, по большей части, дата-центров. У нас довольно много серверных стоек — 2700, они расположены на площади в 8300 кв. метров, окутаны огромным количеством оптоволокна — 245 км — и потребляют довольно много мегаватт энергии (14,4 МВт электрической мощности).
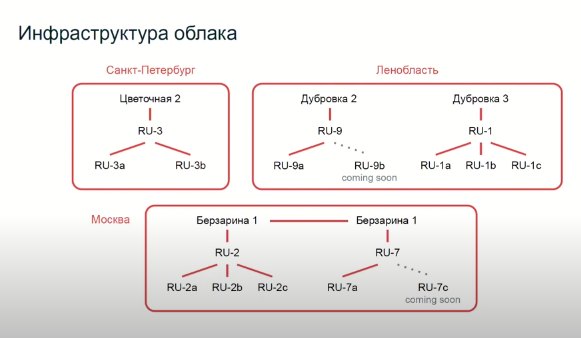
Немного про инфраструктуру. Опять же без технической информации. Вся наша облачная инфраструктура базируется на нескольких дата-центрах, они расположены в разных городах. “Цветочная” в Санкт-Петербурге, “Дубровка” в Ленобласти и “Берзарина” в Москве. В свою очередь, это такие глобальные точки.. если спускаться чуть поглубже, то дальше там под ними есть абсолютно независимые друг от друга дата-центры, аппаратная составляющая, которая в принципе работает автономно, каждый из них подключен двумя сетями, для того, чтобы это работало довольно-таки устойчиво.
Но не железом единым, как говорится. Если посмотреть чуть выше, то вся эта инфраструктура работает благодаря огромнейшему количеству софта и людям, которые этот софт пишут и которые его используют.
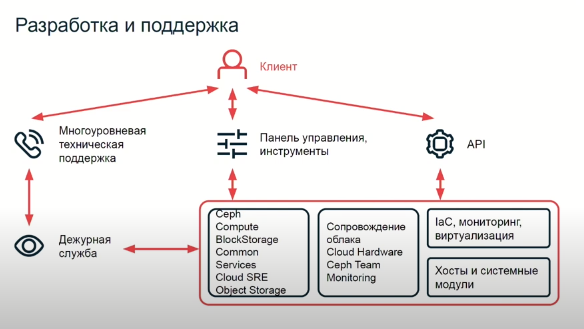
На слайде, внизу, лишь малая часть наших направлений, наших команд. Рядышком я отобразил дежурную службу, чтобы немного ее выделить. И, конечно же, клиент, который взаимодействует со всей этой инфраструктурой с помощью API (довольно высокоуровневой историей), панели управления, и, если что-то не получается, всегда есть возможность обратиться в техническую поддержку. Техническая поддержка многослойная, разной сложности вопросы закрывает, ну и плюс есть направления для клиентов, которым важен какой-то индивидуальный подход. Если говорить про сотрудников, это достаточно большое количество ребят, профессионалов в своей области. Конечно же, они распределены по командам, которые работают в разных направлениях. Вот в общих чертах о нашей инфраструктуре.
Объем довольно большой, несколько городов, несколько сотен сотрудников, много процессов, много инструментов.
Здесь технарям будет интереснее. Расскажу про наш мониторинг, как он устроен. Начать стоит с того, что вся инфраструктура, аппаратная и виртуальная, все эти серверы, на них стоят эспортеры от Prometheus и собирают данные по их работе. Стоит сказать о том, что вся наша инфраструктура описывается в NetBox, знакомый вам инструмент для описания компьютерных сетей до самых глубоких мелочей. Если вспомнить предыдущий слайд, там прям две с лишним тысячи стоек, все это описано.
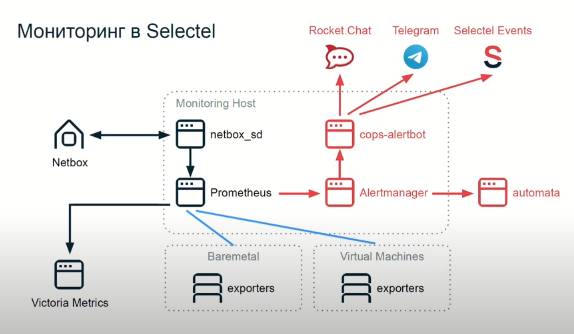
Непосредственно о самом мониторинге. Он состоит из четырех основных вещей, это netbox_sd, Prometheus, Alertmanager (от Prometheus) и “самонаписанный” cops-alertbot.
- netbox_sd собирает список всего оборудования, которое нужно опросить, передает его Prometheus
- Prometheus просто-напросто опрашивает каждый сервер, аппаратный или виртуальный, собирает все данные, которые собирает экспортер, каким-то образом агрегирует, группирует и отправляет на длительное хранение в VictoriaMetrics. Там все хранится около года: все данные по абсолютно всем нашим серверам. Затем Prometheus передает это все в Alertmanager.
- Alertmanager все сообщения группирует, обрабатывает по определенным правилам и формирует уже из них сообщение, которое нужно передать дальше, так называемые “алерты” (что понятно из названия).
- После этого данные попадают в automata. Это сервис по работе.. банально запускает скрипты, чтобы какие-то вещи автоматизировать (на самом деле, пока еще не так много вещей, которые мы бы хотели автоматизировать, но тем не менее).
- Дальше по цепочке наверх данные попадают в cops-alertbot. Это бот, который собственно уже эти алерты и данные группирует, “тегирует”, вешает какие-то лейблы на них и передает далее в человеческий интерфейс: Rocket.Chat, Telegram и Selectel Events. Selectel Events — это приложение в духе Alertmanager, которым пользуется наша техническая поддержка. В Telegram и Rocket там уже немного другие алерты приходят, на которые нужно реагировать здесь и сейчас. Это будет полезно, далее я буду рассказывать о работе дежурной службы.
С ходом времени наша инфраструктура все разрасталась и разрасталась, ни для кого из нас не секрет, что любая инфраструктура с ростом становится сложной в эксплуатации. В первую очередь, вместе с количеством оборудования растет количество задач, их разнообразность и разнородность. Мы тоже с этим столкнулись, потому что задач стало огромное количество, банальным набором людей это перестало закрываться — масштабироваться приходилось довольно сильно.
Также мы стали получать плотный поток сообщений от мониторинга. Вместе с ростом аппаратной составляющей, виртуальных серверов, они также присылают нам какие-то сообщения.
Ну и конечно нам стало тяжело коммуницировать, потому что команды разрослись, стали дробиться. У каждого свои цели, KPI, это все приводит к своего рода сложностям в коммуникации.
Это основные вещи, с которыми мы столкнулись. Стали думать, что с этим делать. Решили выделить, разделить, скажем, задачи на профильные направления. Тут я разделил на две части для простоты понимания. Мы, в общем-то, ничего не стали делать для работы по развитию облака, потому то оно как ехало по спринтам, так и едет. Про него вам рассказывать не буду. Отдельным как раз таки направлением, то, чем стал заниматься я, это стали задачи оперативного направления, на которые нужно реагировать здесь и сейчас.
Мы выделили три основных больших области, которые нам нужно оперативно закрывать:
- работа с сообщениями мониторинга, обслуживание инфраструктуры
- реагирование на аварии и сбои, решение инцидентов
- помощь саппорту в дебаге сложных кейсов. Саппорт часто приходит с непонятной проблемой, в которой нужно покопаться.
Решением для этих задач стала дежурная служба. Расскажу вам про нашу команду, она совсем немногочисленная: мы справляемся силами 4 человек + сверху я. Что она собственно дает? Возможность справиться с мониторингом, с авариями, с задачами от саппорта. Все довольно просто. Мы заранее посмотрели на рынок и попытались набрать ребят, у которых довольно широкий опыт работы с абсолютно разным оборудованием: серверным, сетевым. У одного из наших сотрудников есть даже военный опыт работы.
Далее нам нужно обеспечить их достойным уровнем рабочих условий, инструментария: fullstack Linux, Grafana, Prometheus, OpenStack, Jira. И, конечно, техническое обеспечение. У каждого нашего сотрудника корпоративный ноутбук, обеспечено полностью рабочее место, возможность к нему подключиться 24/7. График у нас 2 через 2 дневной, но по ночам мы остаемся на связи и всегда доступны.
Дальше перейду к инструментам, отойдем от людей. Расскажу про наш мониторинг. На слайде два конкретных примера сообщений, которые приходят нашим сотрудникам в Телеграм. На них мы и реагируем, оно выглядит так, как мы считаем, должно выглядеть сообщение, чтобы быть информативным и полезным.
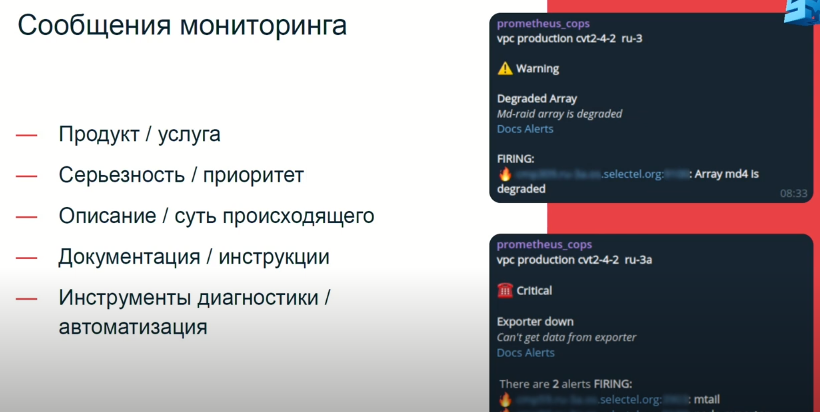
В первую очередь мы отображаем продукт или услугу, здесь это vpc (Virtual Private Cloud) и дата-центр, в котором оно находится. Далее — серьезность или приоритет. В примерах — critical и warning. Critical требует сиюминутной реакции, поэтому значок телефона: в этом случае ребята из саппорта, получая такой же алерт, и при отсутствии быстрой реакции от дежурных специалистов, они им звонят (саппорт работает фулл-тайм 24/7).
Затем, если мы посмотрим далее на сообщение, увидим описание того, что происходит. В примерах деградация сервиса, полная недоступность экспортера. Потом мы видим ссылочки на документацию, полезная штука. Она нужна для того, чтобы сотрудник не помнил всегда и не держал в голове, что конкретно алерт значит, что с ним нужно делать, потому что их очень большое количество, запомнить все просто нереально: даем возможность быстренько перейти, посмотреть, освежить в памяти. Здесь 2 ссылки: одна ссылка ведет на описание того, как работает этот алерт, какая у него механика; вторая ссылка на инструкцию о том, как с этим алертом нужно работать, прописаны конкретные действия сотрудника.
Ну и, конечно, это инструменты диагностики и автоматизации. Вот здесь, если посмотреть, где “заблюрена” ссылка, она ведет на дашборд в Grafana, на котором отображаются все данные по конкретному серверу/сервису/приложению за период плюс-минус время от возникновения сложности. В зависимости от алерта, эти ссылки разные. Таким образом у нас все настроено, опытным путем вычислили, что так работает.
Далее стоит поговорить об аварийном регламенте. Каждый из вас сталкивался с авариями, сбоями, и не исключено, что любое сообщение в мониторинге перерастает в аварийный регламент.
Отметим стартовую и конечную точки. Стартовая — само сообщение-алерт или сообщение от клиентов через саппорт, а конечная — завершенный инцидент. Пройдем по всему процессу, который мы построили.
После сообщения о том, что происходит, должна появиться какая-то первая реакция. Здесь подключаются админы, и, как я уже сказал, они могут подключиться сразу, или, если реакции от них не последовало, саппорт начинает звонить сотруднику. Естественно, график дежурств общедоступен. Дежурный админ подключается, оценивает критичность, понимает сложность, какой сервис затронут, сколько клиентов пострадало (и пострадало ли вообще), все вот эти вещи; и начинает разбираться в этой проблеме.
Дальше регламент как бы раздваивается, идет по двум разным веткам. Где все довольно просто, сотрудник справляется сам; либо же авария какая-то критическая: отвалился регион, или там упало несколько стоек разом. В этом случае сотрудник должен подключить профильных сотрудников, которые занимались продуктом или сервисом, чтобы помощь была быстрой и точной.
На этапе, когда подключается технический специалист уже профильный, администратор дежурной службы занимается уже больше не устранением аварии, не решением инцидента, а его оформлением, способствуя удобству и скорости решения задач. При этом, он может подключить несколько сотрудников в зависимости от того, что сломалось.
Подключение идет не самим сотрудником, пишем сообщения в чат для саппорта, саппорт уже понимает, кого нужно будить — идет, звонит требуемым сотрудникам.
Сейчас я расскажу вам про наш опыт. Произошло все это дело в пятницу, середина апреля, наш реальный кейс. 06:22 утра. На слайде вырезанный реальный скриншот, в действительности было больше: мы получаем порядка 300 сообщений разом. Из этих сообщений сразу видно, что проблема сетевая, отвалились сетевые диски. Мы сразу понимаем, что у клиентов, которые пользуются этими сетевыми дисками, не работают сервисы. Далее, во время диагностики, мы понимаем, что затронут целый регион RU-2 в Москве, это сотни клиентов. Простой сервиса в итоге составил около 10 часов. В активной фазе устранением занималось 20 сотрудников: с 6 утра до 4 вечера. При этом, стоит отметить, что в самом начале ребята отработали по инструкции, претензий к моим сотрудникам не было.
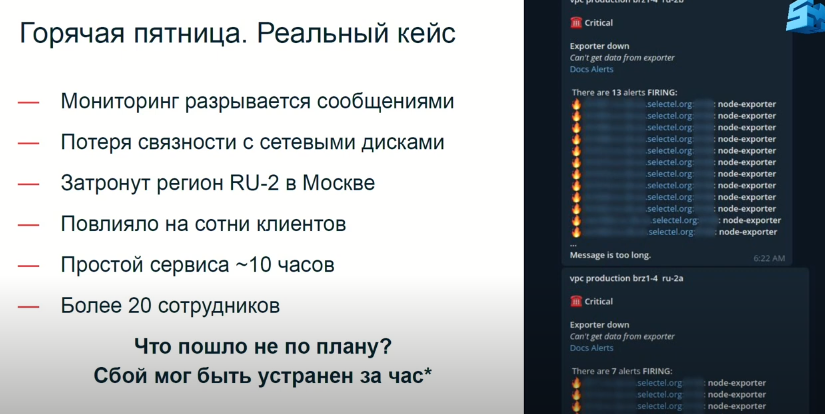
Как вы думаете, что пошло не по плану, если сбой мог быть устранен за час? Давайте погенерим гипотетические сложности.
Так, прозвучало несколько версий, близких к реальности. Давайте расскажу. Не зря на слайде нарисованы грабли. Действительно, пятница была довольно горячая, и, по факту, к тому, что это все затянулось, привела череда факапов. В один день сложились все звезды.
Начать стоит с того, что наши дисковые хранилища сейчас проходят через довольно длительный и сложный рефакторинг всей инфраструктуры. Не буду углубляться в детали, но в целом процесс длительный и асинхронный. Разные этапы работ мы проводим в разное время в зависимости от наличия ресурсов, инструментов и так далее. Команда инфраструктуры подготовила сетевой конфиг для будущей аппаратной платформы, его, естественно, не применили, положили до лучших времен, когда будет обновлена аппаратная составляющая. И в 6 утра, по независимым от них причинам, неконтролируемо применяется этот конфиг. То есть текущая инфраструктура начинает работать с новым конфигом, который должен был быть применен только после аппаратного обновления.
Все падает. На этом этапе подключается уже дежурный администратор. Подключается, диагностирует проблему как сетевую и подключает сетевых специалистов. Вот они сидят на пару, разбираются, решают сетевую проблему. На самом деле, уже прозвучал ответ, проблема была диагностирована ошибочно. Ребята два с лишним часа занимались решением именно этой сетевой проблемы: разбирались в оборудовании, что-то переключали, что-то тестировали, проверяли гипотезы. В итоге, сделали сильно хуже. Вот уже второй факап. Установка нового конфига, видимо, была связана с обновлением Netplan, который потянул какие-то зависимости, они перезапустили сервисы, и сервисы уже запустились с новым конфигом. Вот такая история, если очень коротко, в техническую часть я не очень погружался. Причем, стоит отметить, что это произошло за месяц до этого момента.
В общем, начинается рабочий день, 9-10 утра. Наша инфраструктурная команда приходит на работу и понимает, что что-то идет не так. Разбираются в проблеме буквально за полчаса и устраняют ее: откатывают мисконфиг. Собственно, все вроде начинает работать, но нет. Ребята на предыдущем этапе, проверяя гипотезы на сетевом оборудовании, все сильно усложнили.
Короче говоря, мы имеем реальную проблему, у нас лежит пол-Москвы. Мы стараемся все поправить, у нас там начинаются действительно аппаратные сложности с сетевым оборудованием и так далее. Решаем мы эту проблему в течение всего оставшегося дня. Дальше уже детали. В итоге в 4 часа вечера мы кое-как подняли, понятно, что для разных клиентов время простоя было разное, но максимально — порядка 10 часов.

Что мы сделали в итоге? Стоит посмотреть еще раз на наш аварийный регламент. Мы не проговорили, что происходит после решения инцидента. Важно понять, что происходило, понять, что было не так, в каких моментах мы допустили ошибки. Важные этапы в аварийном регламенте: анализ слабых мест и формулирование задач по устранению этих проблем.
Как вы думаете, что мы могли тут сделать? У нас налицо три или четыре факапа — это недостаточное планирование (применили не так конфигурацию); ошибка в диагностике сотрудника, который сделал неправильные выводы и подключил не тех сотрудников; ошибочные действия при проверке гипотез; недостаточная организация всего это действа в итоге (начало подключаться много людей, поняли, что в итоге просто бегаем, у всех все горит, мало что получается в итоге).
Мы долго потом разбирались с этим вопросом. Как мы проводим разбор полетов? Во-первых, мы собираем документ с обязательным одновременным редактированием для того, чтобы каждый сотрудник мог зайти и оставить свою версию событий, записать свои активности и результаты. Этот документ мы заводим уже на этапе устранения аварии, его же мы используем как некое общее инфополе, чтобы там синхронизироваться, коммуницировать и так далее. Самым удобным вариантом стал Google Docs. Каждый может использовать удобный ему инструмент.
По факту, после того, как мы закончили устранение проблемы, каждый сотрудник отписывается. Временная метка, фамилия, что конкретно сделал, к чему привело. Так мы получаем полную хронологию событий.
Уже остывшие, как правило, на следующий день садимся и начинаем разбираться, что произошло. Смотрим на всю эту хронологию событий, понимаем, где, что пошло не по плану, что стоило бы улучшить. Собственно, ставим задачу, намечаем результат и, при необходимости, повторяем. Такая вот несложная история.

Что конкретно сделал я для того, чтобы как-то минимизировать ошибку? Начать стоит с того, что я просто-напросто сел и посмотрел на регламент, как говорится, начинать надо с себя. Посмотрел на регламент, критически его оценил и переписал.
Что сделали? Мы стали подключать сразу всех ключевых сотрудников, чтобы минимизировать ошибки на этапе диагностики, потому что группа молодая, мы работаем всего полгода. Естественно, на текущий момент вероятность ошибки у новых сотрудников еще довольно велика. Поэтому дежурный администратор, если понимает, что что-то идет не так, отправляет сообщение в саппорт, и саппорт подключает сразу трех сотрудников: это инженеры электропитания в ЦОДах, это сетевая служба, это инфраструктурная команда. Таким образом, мы закрываем основные вещи, они подключаются, проверяют, если что-то в их зоне ответственности — подключаются к работе.
Перераспределили роли и задачи таким образом, чтобы они как-то более-менее подходили по функционалу, своей специфике, навыкам и умениям сотрудника. До этого момента мы просили от сотрудника дежурной службы некоторого рода администрирования этого процесса, но опыт показал, что технический специалист, администратор, ему довольно сложно начать коммуницировать, организовывать процесс и стыковать работу нескольких сотрудников. На текущий момент, если что-то происходит не так, к организации процесса подключаюсь я, с сотрудника эту задачу снял.
Затем, в обязательном порядке, мы собрали общедоступный список всех плановых работ, сделали как раз после этого случая, потому что у нас была рассинхронизация. Мы слабо понимали, кто чем занимается, и все это оставалось на словах. Сейчас мы имеем список, он дублируется в Confluence (а по факту список задач в Jira): текущие и завершенные работы.
Далее такие, процессные истории. Повышаем компетенции сотрудников, разбираем ошибки, сами сотрудники участвуют в анализе проблем, мы их обучаем, переписываем регламенты, стали проводить тестовые аварии.
И, конечно, мы работаем над внутренним улучшением инструментов диагностики: Grafana, скрипты, все, что экономит время сотруднику и упрощает работу.

Подходя к завершению своего выступления, хотел собрать для вас своего рода шпаргалку. После того, как я вам ее покажу, ответьте, пожалуйста, как у вас закрыт каждый из этих пунктов?
- Начать стоит с аварийного регламента. Это та вещь, о которой стоит подумать сильно заранее. Вам нужно прописать основные этапы, зоны ответственности, конкретные действия. Что я имею в виду? Во-первых, вы должны сами понимать весь процесс того, каким образом с возникновением аварий ваши сотрудники будут работать; кто с кем и как коммуницировать; кто и как переписываться; какими должны быть сообщения, и какая информация должна быть донесена. Все это должно быть прописано по пунктам, чтобы каждый из сотрудников сел, почитал и, главное, понял.
- Обучение сотрудников. Если не понял, вам нужно рассказать, проверить, что усвоил. Возможно, что-то потребуется отрепетировать; ролевые игры, тестовые аварии, да любые вещи, которые позволят проверить, что сотрудник усвоил.
- Сообщения от мониторинга. Это основной инструмент дежурного администратора. Оно должно быть коротким, информативным, понятным. Если вы будете сыпать ворнингами, у вас просто замылится глаз, из-за чего вы обязательно пропустите критический момент.
- Инструменты диагностики и сбора данных. Здесь у каждого свои, наверное, реализации. Но по сути это скрипты, визуализация (та же Grafana), чек-листы (тут подумайте, что нужно проверить, чтобы убедиться, что ваш сервис работает), какие ключевые вещи ваш сотрудник должен посмотреть. Это должно быть написано, чтобы сотрудник не запоминал этого всего и не держал в голове.
- Простые коммуникации. Тоже довольно важная штука, про которую мало кто вспоминает. Текстовый чат для аварий — заведите его до того, как произойдет авария. Ваш сотрудник не должен думать, как это сделать, организовать, кого собрать. Там уже должны быть собраны люди, которые могут быть полезны. Сделайте возможность подключаться голосом — Zoom, Meet. И позаботьтесь о возможности вести документ с одновременным редактированием.
- Из практики знаю, что мало кто проводит анализ произошедшего. Или только самых крупных аварий и сложных ситуаций, проводите анализ даже мелочей. Во-первых, это post mortem — садитесь, разбирайте всю хронологию, понимайте, что пошло не так. Если устранить проблему совсем невозможно, попробуйте хотя бы минимизировать шанс ее возникновения.

ВОПРОСЫ СПИКЕРУ
1. — По поводу работы над ошибками. Опыт показывает, что есть смысл выводить не только плановые работы, но и вообще любые, в том числе, аварийные, потому что любая дежурная группа должна знать, что происходит прямо сейчас. Это предложение вдобавок к работе над ошибками.
— Хорошее замечание. Плановые работы мы собираем списком, аварийные же распространяются по общим чатам. Постфактум же есть список отдельный с репортами и так далее. Но предложение хорошее, спасибо.
2. — У меня такой вопрос. Ваша оперативная смена смотрит какие-то алерты по прогнозам? Грубо говоря, у клиента в день стабильно прирастает 100 Мбайт дискового пространства, мы понимаем, что через месяц оно кончится. Какие-то такие вопросы в ведении вашей службы находятся?
— Хороший вопрос. Что я могу сейчас в этой области затронуть.. это наверное steal time, такая извечная проблема. Нагрузку на серверы мы отрабатываем превентивно, чтобы уменьшить количество обращений. В таком же контексте мы, наверное, не думали, а что можно сказать.. ну опять же, мы мониторим состояние тех же дисков и заполняемость, их latency, скорость работы. Если говорить про прогнозы, то ничего такого не делаем.
— Опять же, по своему опыту, напрасно не делаете. Это позволяет добавлять в план соседним службам какие-то задачи, которые даже может и были запланированы, но требуют более быстрого решения. Мы понимаем, что у нас передатчик в трансивере деградирует быстрее, чем мы планировали. По плану замена через полгода, а мы понимаем, что он умрет через месяц. Это укладывается в идеологию оперативной службы, на мой взгляд.
— Соглашусь. Спасибо за рекомендацию.
3. — Подскажите, пожалуйста, используете вы на своих авариях свертывание аварий? Пример. У вас в дата-центре живет 100 сервисов, условно. Дата-центр упал, ваши инженеры видят 100 аварий. Они пытаются разобраться оптом, или они видят, что упало все и без автоматического погружения туда?
— Наверное, вы имеете в виду, какие-то готовые сервисы, которые группируют и объединяют во взаимосвязанные цепочки?..
— Да, я об этом.
— В явном виде такой штуки нет, но есть группирование уже готовых алертов, в одно большое сообщение, из которого уже понятно, что происходит уровнем выше.
4. — Как известно, мониторинг — это три больших повторяющихся шага. Нужно решить, какие данные собирать, как их интерпретировать, и третий шаг — ваши регламенты, которые вы реализуете, то есть, что с ними делать. Вопрос: как в вашей компании реализовано изменение, проектирование, принятие новых регламентов, если это не секрет?
— Наша служба находится “наверху”, по сути мы настраиваем работу с уже готовыми инфраструктурами, с готовыми сообщениями. С другой стороны, мы конечно даем обратную связь ребятам, которые разрабатывают мониторинг, анализируют данные, готовят алерты. Мы в этом мало участвуем, лишь даем обратную связь по удобству.
5. — Чем занимается дежурная смена вне устранения сбоев?
— Там много интересного. Это задачи от саппорта, обслуживание самой инфраструктуры. Приходит много алертов о том, что какой-то диск умер, или его производительность упала. Такой поток очень большой.
— Я имел в виду, это работа только по алертам? Вы сами не анализируете возможные проблемы?
— Пока это находится в зачаточном состоянии. Пока весь анализ сводится к ручному анализу происходящих событий и отгрузки этих событий для обсуждения голосом. Но какой-то аналитики и статистики пока не собираем. Это то, над чем я сейчас работаю.
6. — Здравствуйте! Мы с нашей сменой работаем таким образом, что профильные специалисты периодически проводят обучение для смены, чтобы они глубже понимали процессы и могли сами что-то сделать. Есть ли у вас такого рода деятельность внутри компании? Откуда смена получает навыки?
— Да, конечно. Шеринг знаний — часть нашей корпоративной культуры. На моем уровне это четыре администратора, которые между собой синхронизируются, плюс мы проводим регулярные встречи. Помимо этого у нас есть обратная связь с разработчиками, с админами, которые занимаются поддержкой.
7. — Есть ли у вас возможность у сменного персонала “по кнопке” выполнить какое-то рутинное действие? Вывести диск из массива, например.
— Да, такие вещи мы делаем. Из того, что произошло при мне (буквально за последние полгода), были переработаны алерты, связанные с высоким latency в дисках, сейчас эта история поправлена, мы таких алертов в принципе не получаем. Еще был момент, это ввод-вывод дисков, если что-то происходит, то там это как-то автоматизировано, пара кликов и все. Если мы понимаем, что какой-то алерт можно автоматизировать, мы это сразу скриптуем.
8. — Скажите, пожалуйста, после этого инцидента вы не ввели такую процедуру, что критичные изменения конфигурации и любые другие действия, которые могут привести к отказу значимой части или всей инфраструктуры, должны выполняться только с ручной конфирмации?
— Смотрите. Вопрос по делу, да. Так и предполагалось, это должно было быть применено вручную. Ребята, конечно, провели работу над ошибками, но не могу сказать точно, что они сделали. Это, такой, больше факап инфраструктурный. Но сейчас поменялся подход к проведению такого рода вопросов. Во-первых, они все строго регламентируются, во-вторых, они хранятся все в истории предстоящих плановых работ, в-третьих, повысилась ответственность, конечно. Что конкретно происходит у ребят в команде, честно, не скажу.
9. — Такой вопрос. Отбивки об авариях у вас в чат приходят, или у вас только аварийные сообщения? “Зачищенные”, неактуальные аварии.
— Да, любой алерт имеет свой артикул, имеет свою активную фазу..
10. — А, тогда еще такой. Резервирование дежурной службы вообще есть? Может, какой-то филиал?
— У нас одна команда, один офис. Людей не резервируем, все резервируется на автоматике. Все, что может сбойнуть, оно дублируется. Да даже люди дублируются, у нас два человека в смене. Плюс остальные администраторы работают на удаленке, этот вопрос закрывается сам собой.
— У вас есть нормы нагрузки на дежурного специалиста?
— На текущий момент нормативов нет, мы стараемся обходиться без них. Это все перерастает в KPI, показатели и т.д. В компании собраны ребята со взаимоответственностью и выручкой, каждый делает работу не из-за целей, а потому что ему это нравится. Но мы расширяемся, у меня вот открыта вакансия. Растущую нагрузку компенсируем комплексно: это автоматизация процессов (какие-то простые процессы на нашем уровне автоматизируем сами; более сложными историями занимаются сторонние ребята), это их настройка, чтобы все было оптимизировано; расширение штата.
11. — В зависимости от инцидента, как у вас организовано формирование чата? Один критический чат на все инциденты и алерты ,или вы собираете динамически каждый чат отдельно? И сколько, в среднем, в таком чате присутствует членов команды?
— Как я и говорил, такой чат должен быть создан заранее. Он есть отдельно у сетевиков, отдельно по нашему облаку, инженерно-технический отдел и т.д. В каждом из этих чатов есть я и мой дежурный. Соответственно, если происходит сбой в нашем облаке, в продуктовом чате есть все заинтересованные: от администраторов до менеджеров и владельцев этого продукта. Поэтому информацию об этом получают все сразу. Если, допустим, администратору нужно подключить других профильных сотрудников, то он раскидывает в каждый из этих чатов ссылки на документы, информацию. А дальше все равно, вся коммуникация происходит в общем нашем чате или в продуктовом. Аварийные чаты заведены у каждого отдела. Количество человек не считал, не скажу. Но там прям десятки людей. Эти чаты, хочу отметить, используются только для критических ситуаций.
12. — Какой уровень инфраструктуры как кода у вас внедрен? Остались ли какие-то ручные операции?
— Хороший вопрос. Честно, по технической части я вам конкретики не дам, но да, какие-то операции ребята выполняют вручную.