“Victoria Metrics agent - комбайн для мониторинга” (Николай Храмчихин, Victoria Metrics)
Добрый день, меня зовут Николай Храмчихин. Сегодня я расскажу о vmagent’е, нашем комбайне для мониторинга.
Вначале краткий экскурс в историю — с чего все началось и зачем был разработан vmagent. Сначала была VictoriaMetrics, это быстрая и простая в установке БД для временных рядов. Она принимала данные в себя из Prometheus по remote_write-протоколу. В ходе эксплуатации Prometheus’а мы и наши клиенты столкнулись с определенными проблемами. Проблемы были актуальны на тот период — где-то полтора года назад. Сейчас, возможно, что-то изменилось, и они уже не актуальны.
В первую очередь, Prometheus потреблял много оперативной памяти (RAM), это приводило к ошибкам out-of-memory. Он глючил и тормозил после unclean shutdown, думаю, многие сталкивались с этой проблемой — его сложно запустить после этого. Нужно было либо удалять все данные, либо добавлять ему оперативной памяти.
Также он мог терять метрики, если удаленное хранилище было недоступно какой-то период. Это было очень неприятно — на графиках были пропуски, и работать с удаленным хранилищем было невозможно.

В ответ на все эти проблемы был разработан vmagent как легковесная замена Prometheus.
Давайте рассмотрим его основные возможности. В первую очередь это, конечно, сбор метрик по pull-модели, как это делает Prometheus. В этом случае vmagent отправляет http-запросы на цели и получает от них список метрик. Кроме этого, он умеет получать метрики по push-модели, когда разнообразные клиенты (Telegraf, statsd и проч.) могут отправлять в него метрики.
Помимо этого он может фильтровать собранные метрики. Есть определенный набор правил, по которым это можно сделать, и модифицировать имена метрик с их лейблами.
Конечно же он может сохранять метрики в удаленное хранилище, как это делал Prometheus, по remote_write-протоколу. С его помощью можно настроить репликацию в несколько хранилищ, главное, чтобы они понимали протокол. Например, можно записывать в VictoriaMetrics, в vmagent, в Cortex и в некоторые другие удаленные хранилища. При недоступности хранилища vmagent не теряет метрики, у него есть дисковый буфер (на каждое удаленное хранилище отдельный).
Самое главное: он использует небольшое количество ресурсов CPU и оперативной памяти. Конечно же, он легко устанавливается: у него всего один исполняемый файл без внешних зависимостей.

Как осуществляется сбор Prometheus-метрик? Мы сделали возможность использования конфигурационного файла Prometheus. Vmagent поддерживает global и scrape_configs секции конфигурационного файла. Можно настроить как static config со статических таргетов, так и с помощью service discovery от провайдеров получить список таргетов и уже использовать их. В данный момент vmagent работает с основными, такими как Kubernetes, Amazon EC2 и остальные. Если какого-то service-провайдера нет в списке, всегда можно открыть issue на Github.com, и мы сразу все добавим. Также как и Prometheus, vmagent умеет в релейблинг.
Помимо этого, у vmagent есть дополнительные фичи. Это, в первую очередь, кластеризация. Можно разделить таргеты между разными vmagent’ами при помощи простой конфигурации. Это бывает полезно, когда не хватает ресурсов одного vmagent’a для сбора метрик, либо можно таким образом распределить точки отказа: если одна виртуальная машина с vmagent’ом вышла из строя, можно продолжить собирать часть метрик со второй машины. Соответственно, достаточно указать количество агентов в кластере и каждому из них присвоить уникальный номер.
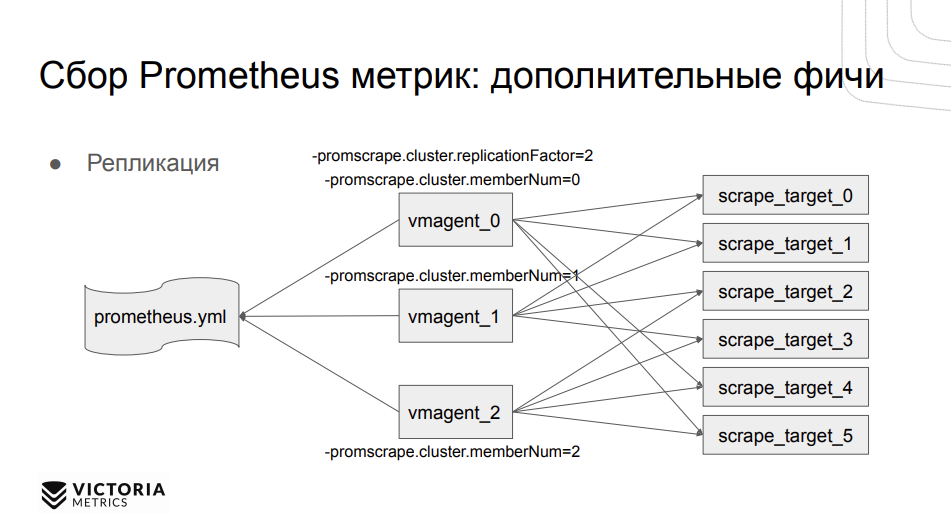
Где кластеризация, там уже может быть и репликация. И да, vmagent умеет в репликацию. Настроив replication factor, можно собирать несколько метрик с разных таргетов.
Одна из важных фичей, которые позволяют vmagent’у использовать небольшое количество RAM — это потоковое чтение метрик. В данном случае, если таргет экспортирует более 10 млн метрик, то потребление памяти будет достаточно большое. Настраивается все достаточно просто: нужно указать stream_parse:true в конфигурационном файле для конкретной job, либо глобально для всего vmagent’а. Prometheus-экспортеры отдают метрики в построчном формате (prometheus text exposition), поэтому vmagent читает первые n-строк, обрабатывает их и отправляет на запись в удаленное хранилище, потом продолжает обрабатывать следующий блок данных, пока не обработает все.
Список принимаемых форматов метрик:
- InfluxDB (http, tcp & udp)
- Graphite (tcp, udp)
- OpenTSDB (http, tcp)
- JSON line
- CSV
- Prometheus text exposition format
- Prometheus remote_write
Та самая фильтрация метрик, о которой я хотел рассказать. Она осуществляется с помощью Prometheus-compatible relabeling, то есть поддерживается весь тот синтаксис, который предоставляет Prometheus для релейблинга. Можно фильтровать по имени метрики, по значению тэгов (лейблов) и по регулярным выражениям. Модифицировать можно с тем же совместимым с Prometheus-форматом. Можно переименовать метрики, добавить новые лейблы, изменить или удалить их.

Где может происходить фильтрация и модификация метрик? В vmagent’е она может происходить практически везде. Можно настроить в конфигурационном файле на уровне relable_configs, в этом случае релейбелинг будет применяться, когда vmagent определяет таргеты, получая список таргетов от Kubernetes’а.
Во время сбора метрик можно настроить metric_relabel_configs. На этом этапе уже не будут доступны металейблы от Kubernetes’а. Это нужно делать немного заранее. Перед записью в remote storage тоже можно делать релейбелинг, как для каждого хранилища, так и глобально для всех. И да, релейбелинг работает как для push-метрик, так и для pull.
О других возможностях vmagent’a. Он может ограничивать скорость записи метрик в удаленное хранилище. Настраивается это для каждого хранилища отдельно или глобально для всех. Это бывает полезно, когда удаленное хранилище недоступно, vmagent забуферизировал метрики, и ему нужно записать большое количество метрик в удаленное хранилище, что может его перегрузить. В данном случае можно ограничить количество записываемых метрик в секунду.
Совсем недавняя фича — можно ограничивать количество уникальных метрик (high cardinality) в час и в день. Соответственно, это может спасти от ошибок конфигурации экспортеров, когда они начинают неправильно работать и выдавать высоко кардинальные метрики. Это очень сильно нагружает БД, так как хранение уникальных метрик грузит RAM и CPU, а регистрация новых метрик ID достаточно дорогой процесс. Для улучшения сжатия данных можно ограничить количество знаков после запятой (настраивается для каждого хранилища).
Где и как можно внедрить vmagent? И какие конфигурации могут быть? Самая простая и логичная — легковесная замена Prometheus. Если у вас есть связка с Prometheus, которая пишет данные в VictoriaMetrics, можно его остановить и запустить с тем же конфигурационным файлом vmagent и указать запись в удаленное хранилище VictoriaMetrics.
Для настройки алертинга, если вы используете его вместе с Prometheus, можно запустить vmalert, он понимает алерты в Prometheus-совместимом формате и умеет отправлять их в Alertmanager.
Также vmagent можно использовать для репликации между несколькими ЦОДами для обеспечения отказоустойчивости. Можно сконфигурировать несколько -remoteWrite.url’ов, и, соответственно, между ЦОДами будут реплицироваться данные.
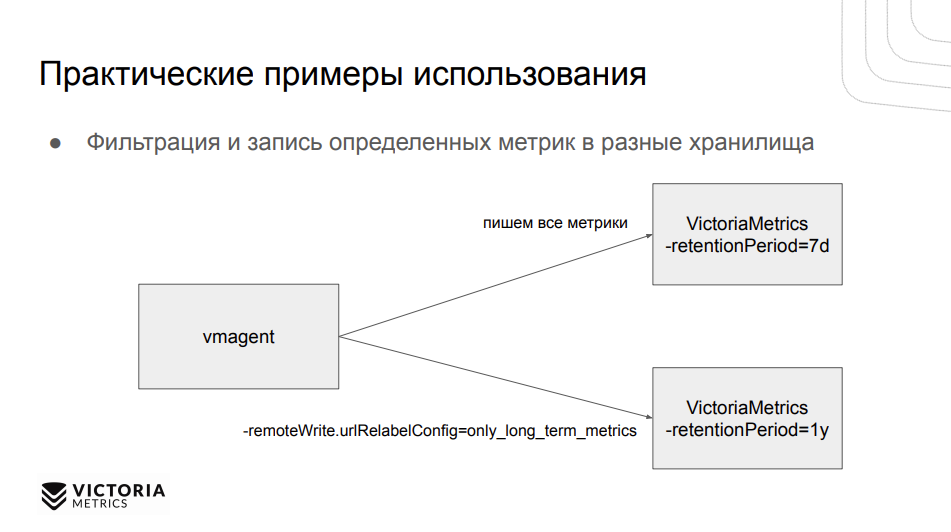
Фильтрация и запись определенных метрик в разные хранилища. Да, один из популярных вопросов, как сделать в VictoriaMetrics разное время хранения разных метрик (retention) в зависимости от лейбла. У нас есть открытый issue, как это сделать на уровне одной базы данных, но сейчас это можно реализовать, запустив две разных VictoriaMetrics с разным временем хранения и добавив для одной из них фильтр, который будет сохранять метрики только с определенным лейблом. А в другую БД писать все метрики. Сверху можно поставить какой-нибудь Promxy или что-то подобное, чтобы он опрашивал две VictoriaMetrics и уже показывал результат в Grafan’е.
При помощи vmagent’а также можно разделять метрики между разными тенантами. Это актуально для кластерной версии, где можно указать два remoteWright.url’а. Первый будет писать в один тенант, другой — во второй, и уже на основе каких-то правил будет маршрутизировать между тенантами эти метрики. Это полезно, чтобы разделить метрики разных команд и окружений.
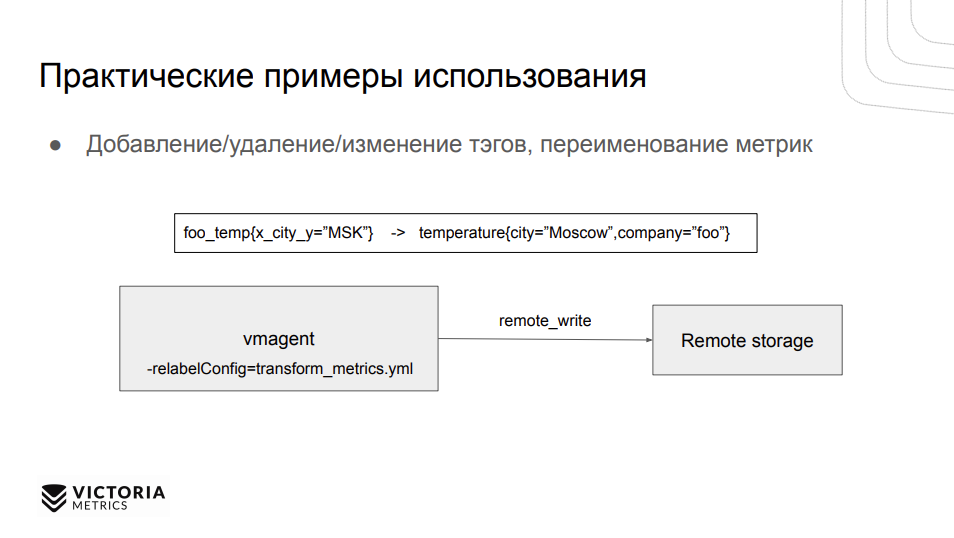
Также можно переводить метрики в “человекочитаемый” формат. Если странный экспортер отдает метрики вот в таком странном формате “foo_temp”, с помощью трансформации и релейблинга сделать более приемлемый формат с понятной температурой и названием компании.
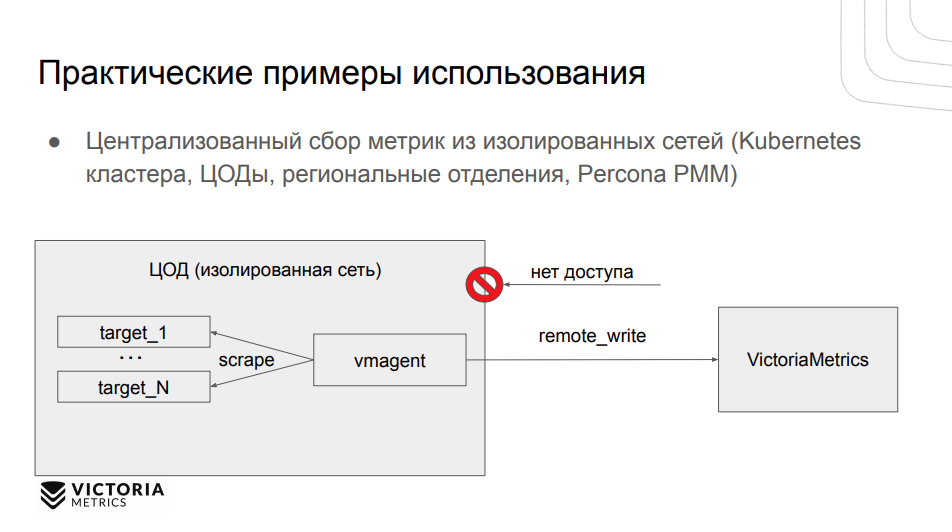
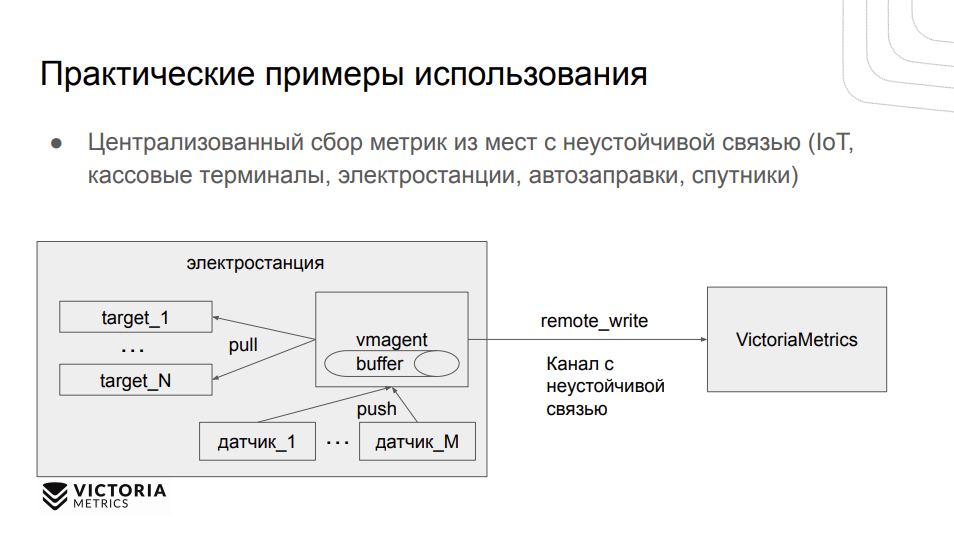
Один из популярных кейсов — централизованный сбор метрик из изолированных сетей. Если применение Prometheus недоступно или сложно настроить, то можно использовать vmagent для сбора этих метрик и отправки в централизованное хранилище.
Также vmagent можно использовать в сетях с неустойчивой связью — кассовые терминалы, электростанции и даже спутники. Если связью с Землей нет, то vmagent будет буферизировать данные, как только связь появится, он их отправит VictoriaMetrics.
Какие у нас планы на будущее? Это поддержка statsd и DogStatsD-протоколов. И мы очень хотели бы разработать новый протокол передачи данных между vmagent и VictoriaMetrics, который потреблял бы гораздо меньше пропускную способность и ее было бы удобнее эксплуатировать в таких случаях, как кассы и спутники. И мы всегда готовы реализовать ваши фичи.
Summary
- pull и push модели для сбора метрик
- Фильтрация и редактирование метрик
- Репликация
- Буферизация на диск при отсутствии связи с удаленным хранилищем
- Простота использования
- Легковесность
- Open Source
ВОПРОСЫ К СПИКЕРУ:
— Можно ознакомиться с какими-то бенчмарками, чтобы сравнить Prometheus и vmagent?
— Мы проводили честный бенчмарк VictoriaMetrics, базы данных, который может не только при помощи vmagent’а, но и самостоятельно собирать данные. Результаты можно посмотреть в документации.
— У Alertmanager есть возможность создания дополнительной crd по поводу рутов и ресиверов, вот для vmalert вы отписывались, что не очень хорошо используется создание дополнительной crd, ну, какой-то другой механизм существует в vmalert, подписывать ConfigMap’ы на основании лейблов или аннотаций, ну или что-то другое, чтобы можно было динамически создавать пары?
— Да, эта имплементация планируется, возможно, в следующем релизе.
— Когда падает remote storage, возрастает ли потребление ресурсов?
— Нет, по идее ничего не возрастает. Есть два буфера — в памяти и дисковый. Второй заполняется после. И потреблять vmagent будет меньше, чем “single-версия” VictoriaMetrics.
— По поводу кластерности для vmagent. Не является ли это дополнительной точкой отказа? Используется ли кворум? Не проще ли использовать просто пару vmagent с дупликацией?
— Кворума нет. Указывается уникальный идентификатор для каждого vmagent’а, он собирает часть данных с определенных таргетов. Можно запустить пару агентов, но будет повышенная нагрузка на экспортеры.
— В планах нет ли замены Alertmanager на что-то свое?
— Нет. Пока есть issue на поддержку Webhook, чтобы можно было отправлять алерты в разные системы.
— Когда теряется связь, данные буферизуются в сжатом или сыром виде?
— На диске они хранятся в сжатом виде, отправляются в бинарном Prometheus-формате.
— Были ли какие-то тесты, когда и связь пропадает и ноды рестартуются, теряются ли метрики?
— Да, они могут теряться, если происходит неправильное включение vmagent’а. Если корректно завершить работу, то ничего не теряется.
Полезные ссылки:
- https://victoriametrics.com/
- https://github.com/VictoriaMetrics/VictoriaMetrics/
- https://docs.victoriametrics.com/vmagent.html
- https://twitter.com/MetricsVictoria