Построение комплексного мониторинга ЦОД для чайников
Константин Струлёв [ЦОДУМ]
Расшифровка видео с доклада на Big Monitoring Meetup 8, состоявшегося в Москве, все мероприятия сообщества Monhouse:
Прежде чем мы углубимся в этот рассказ, я хочу предварительно сказать, что весь доклад построен на моем предыдущем опыте. У меня достаточно заметный опыт в эксплуатации, он весь был связан с мониторингом. Я 9 лет отработал директором по эксплуатации северо-западного филиала МегаФон, в моем подчинении было все, что есть у оператора на северо-западе: мобильная сеть, фиксированная сеть, транспортная сеть, ЦОДы и все остальное. Поэтому с этой темой знаком на практике и здесь попытаюсь изложить результаты этого опыта применительно к ЦОДам, поскольку ими я тоже занимался в МегаФон.
Сейчас я работаю в компании, которая производит программное обеспечение для мониторинга ЦОДов, поэтому это не просто теоретические изыскания — это своего рода методика, которой мы пользуемся. Никого не хочу из собравшихся назвать чайниками, название немного провокационное. Во-первых, в мейнстриме много кто в мире пишет пособия для чайников, а я решил примкнуть. Во-вторых, когда я уже его составил, оказалось, что доклад настолько подробный и детальный и настолько системный, что подойдет для любого чайника. Так это ли не так — сейчас посмотрим.

Что включают в мониторинг ЦОД
Началось все с того, что я, особенно придя вот в то место, где сейчас работаю, стал получать запросы людей на системы мониторинга. Я с удивлением понял, что люди хотят в общем мониторить крайне мало. Хотят видеть температуру, влажность, напряжение на входе, как работают HVAC-оборудование, не течет ли где-нибудь вода и, по большому счету, все. Весь мой предыдущий опыт говорил, что это ничтожно мало. Но ладно, если бы это был один такой запрос, но таких запросов было много.
Почему так?
Я стал интересоваться, почему так? Спрашивать людей: «Ребята, почему вы спрашиваете мониторинг только этого? Почему вы не спрашиваете другие важные вещи?».
Картина выглядит примерно так. Достаточно часто у истоков технического задания на мониторинг, на проект, стоят инженеры. Инженер — узко специализируемый, и он знает свою предметную область. Он ее туда вписал, он знает, что оборудованию не должно быть жарко, у него должно быть напряжение, и оборудование боится воды. Вот, в принципе, все.
Другой заметный фактор: это не первый проект, который человек делает. Три предыдущих проекта, в которых он участвовал, было так. Поэтому он идет по накатанной. Личный опыт: он в каких-то ЦОДах работал, где мониторилось вот это. И это тоже, по старой памяти. И вдобавок где-то начитался, услышал, увидел, кто-то ему рассказал там и с товарищем в журнале прочитал, что вот это — самое важное, самое главное. Ответы на вопросы я не получил.
А как правильно?
Мой опыт, говорит о том, что смотреть надо вообще за всем, что может угрожать, даже теоретически. В противовес есть вот такой минималистический подход. Я задал сам себе вопрос: «Как правильно?» и стал пытаться найти на него ответ.
Мониторинг – что это?
В первую очередь стал искать ответ на вопрос: а что такое мониторинг, для чего нужен, какие задачи решает и кто им пользуется.
Значение в оригинале
Посмотрев в самых разных источниках, я выделил важные ключевые для меня, по крайней мере, моменты. Слово само происходит из латыни, и на латинском языке слово «монитор» имеет основные значения:

«Напоминающий» — специальный человек, который что-то кому-то напоминал. Вот этот человек назывался монитором. «Советник», подающий на суде советы ораторам, такая официальная должность. «Предостерегающий», то есть человек, который о чем-то предостерегает. Мне понравилось здесь слово «предостерегающий».
Что говорит ITIL
Потом я заглянул в ITIL. ITIL сказал: цель практики мониторинга и управления событиями состоит в том, чтобы систематически наблюдать за услугами и компонентами, а также регистрировать и сообщать об отдельных изменениях состояния, определенных как события.
Что говорит наука
Третий академический источник, который тоже мне помог — академический словарь.
Мониторинг — система постоянного наблюдения за явлениями и процессами, происходящими в окружающей среде, результаты которого служат для принятия управленческих решений. Тут у меня более-менее пазл сложился, что я все-таки был больше прав, чем неправ, когда подозревал, что люди просят меньше, чем надо.
Значит, вот сводка, почему необходим мониторинг. Он необходим для предостережения, очевидно, о плохом. Он регистрирует изменения и сообщает о них. Причем, такие изменения, которые мы сами определим, как какие-то плохие, нежелательные. А для чего используется? Используется для обоснования управленческих решений, для того чтобы понимать, что вот в этот момент нужно делать вот это, а в этот момент нужно делать вот это.
Что такое плохо?

Следующий момент, который я стал выяснять: что такое «плохо»? Как понять, о чем мониторинг должен предупреждать?
Главная цель
Как я не искал, как я не думал, у меня ничего, кроме вот экономических составляющих не осталось.
Все предприятия в капиталистической системе живут, действуют и функционируют исключительно для того, чтобы извлекать прибыль и распределять ее между акционерами. Понятно, что когда прибыль увеличивается, это хорошо. Когда прибыль остается той же — это кому как. А вот когда прибыль уменьшается, это всем точно плохо. Поэтому вот первый ответ: плохо — это уменьшение прибыли.
О чём предупреждать?
Хорошо, есть прибыль, которую считают финансисты, а есть технари, есть инженеры, которые видят напряжение, токи. Как одно с другим связать? Где напряжение, а где прибыль?
Стал смотреть дальше. Если очень грубо посмотреть на экономику предприятия, то вот у предприятия есть выручка. Сколько-то денег оно получает от клиентов, и эти деньги оно, опять же очень грубо, делит на два куска. Первый кусочек оно отдаёт на воспроизводство, на поддержку своего производства, на закупки ресурсов, на операционные затраты. И оставшийся кусочек — это его прибыль, которую он тоже распределяет.
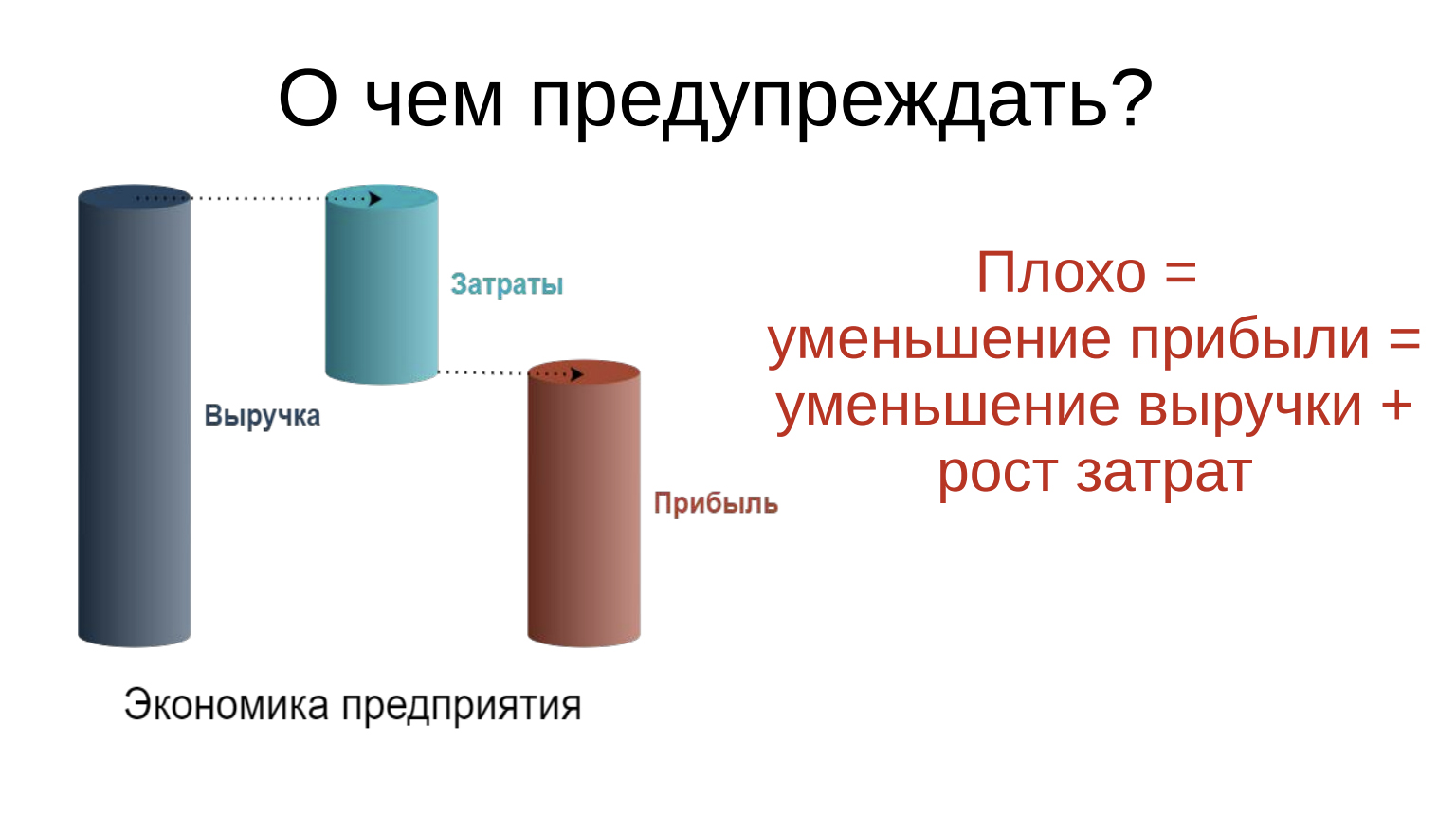
Дальше нужно немножко арифметики. Получается, что плохо — это уменьшение прибыли. А что такое уменьшение прибыли? Это либо уменьшение выручки, либо рост затрат, либо и то, и другое.
На слайде видно, если прибыль уменьшается, то она может при равных затратах уменьшиться за счет уменьшения выручки или при той же выручке за счет роста затрат, или за счет того и другого. Уже понятно, что можно смотреть на затраты. Затраты на шаг ближе к инженеру, потому что инженер все-таки при технике находится, которая эти затраты генерирует, и сам по себе инженер эти затраты генерирует. Для того чтобы найти «плохо», искать нужно все факторы, которые либо уменьшают выручку, либо увеличивают затраты, либо и то, и другое.
Выручка чуть детальнее
Это теоретический расклад. Я просто показываю образ своих мыслей. Тут наверняка можно копать детальнее, но принцип такой же. От чего может уменьшиться выручка? От того, что стало меньше клиентов. “Почему?” – это другой вопрос. Их просто стало меньше, они стали меньше платить денег, и поэтому стала меньше выручка клиентов. Или клиентов осталось столько же, но они стали меньше потреблять. Почему? Другой вопрос. У них стало меньше денег, они нашли какой-то заменитель. Они перешли все в Telegram, они дома поставили свои сервера и сами себя обслуживают. Не важно: они стали меньше потреблять, или мы каким-то образом уменьшили или изменили тарифы так, что при том же количестве клиентов, при том же потреблении, осталось меньше денег для нас.

Что смотреть про выручку
С изменением тарифов, я не знаю, что можно сделать, это не техническая стезя. А вот, например, в уменьшении клиентской базы, уменьшении потребления уже легко всплывают факторы, которые вообще на расстоянии вытянутой руки от инженера находятся.
Например, уменьшение клиентской базы может происходить от снижения покупательной способности. Население просто стало беднее. Инженер ни при чем. Может это от неудовлетворенности качеством и условиям. Или, при том же качестве, на рынке появился кто-то дешевле, и ушли к нему.
Кружочком на слайде обведено то, что инженер держит в своих руках: качество или уменьшение потребления. Опять же, покупательная способность, появление субститутов — тут мы повлиять не можем. Или снижение доступности и неудовлетворенность качеством. Это те факторы, до которых инженеры уже дотянуться могут, которые уже могут посмотреть, как это ложится на технические параметры, посмотреть, как эти технические параметры можно увидеть, как их можно замониторить.

Затраты чуть детальнее
Дальше теперь про затраты. Затраты могут увеличиться из-за повышения стоимости ресурсов, увеличения потребления, увеличения накладных расходов. В эксплуатации это в полный рост.
Что смотреть про затраты
От чего увеличивается стоимость?
Здесь эксплуатация может влиять на это очень опосредованно, можно найти такого поставщика, у которого ресурсы по приемлемой цене. Например, водоканал, у него вода стоит столько, сколько стоит, и нигде ты альтернативный водоканал не найдешь. Чуть полегче ситуация с электричеством, потому что стали появляться альтернативные поставщики, но там тоже не особо разгуляешься.

А вот потребление полностью в руках у инженеров, потому что помимо увеличения нагрузки и технических неисправностей, есть еще неоптимальность процессов и систем. При определенной загрузке они начинают генерировать затраты по экспоненте. Накладные расходы — тоже вещь, которая полностью связана с эксплуатацией, штатом, оптимальностью процессов и техническим обеспечением.
Сервисно-ресурсная модель ЦОД
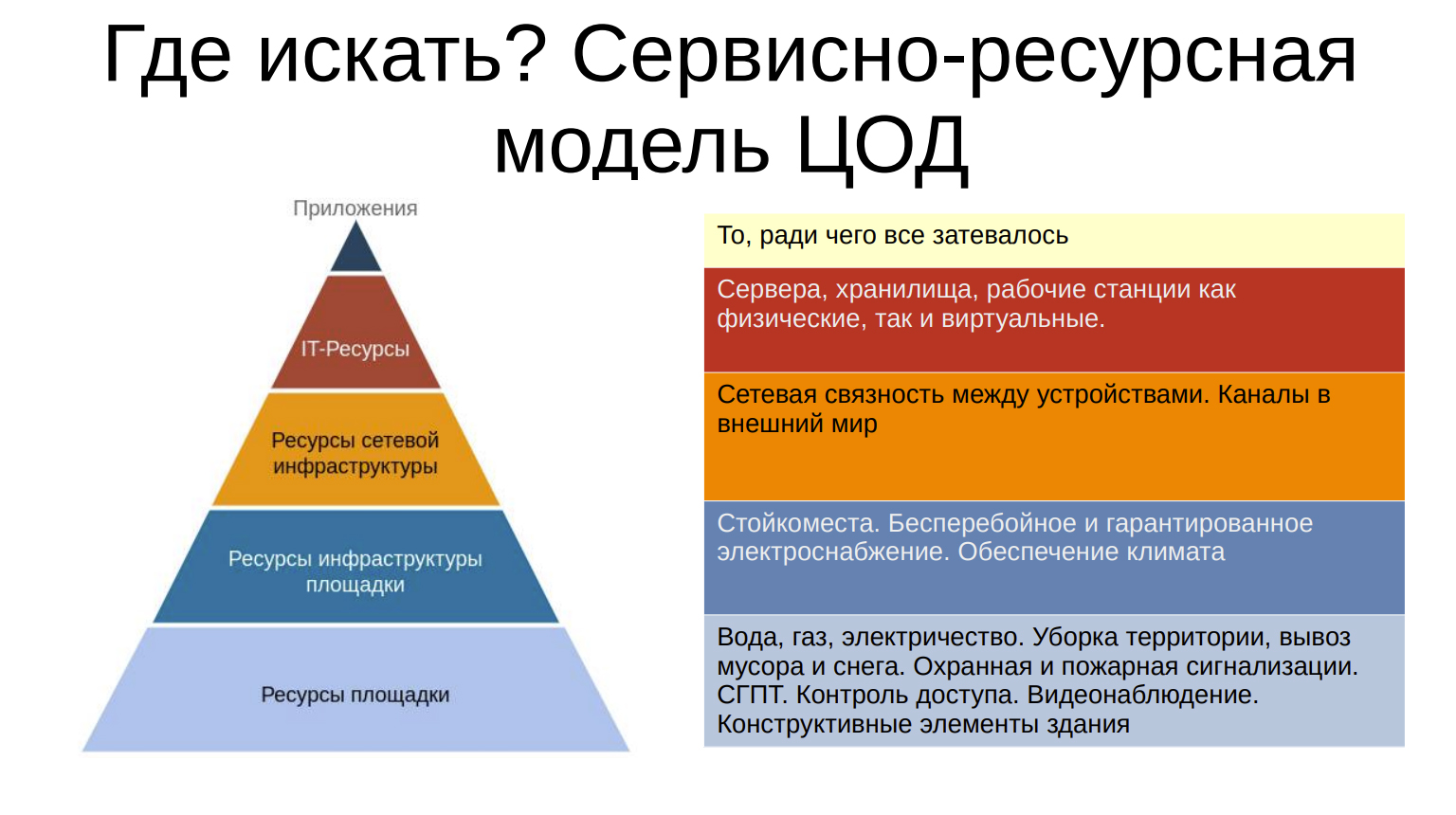
У нас есть ЦОД, есть участок, есть транспортная сеть, есть сервера. Где всё это искать?
Мы нарисовали сервисно-ресурсную модель ЦОДа. Сверху находятся приложения. Это, по сути, то, ради чего затевается ЦОД. Чтобы приложения работали, предоставляли сервисы клиентам и тем самым генерировали выручку.
Сами по себе приложения в воздухе не работают, нужна IT-инфраструктура: сервера, хранилища, рабочие станции и т.д.
Но и сервера, красиво расставленные в комнате, сами по себе работать не будут. Потому что их надо соединить друг с другом, вывести во внешний мир, соединить с клиентами. Таким образом, у нас появляется сетевой слой инфраструктуры.
Даже если мы соединим сервера и протянем провода к клиентам, всё равно ничего не заработает, потому что им нужно питание, охлаждение, размещение. Все это называется: «ресурсы инфраструктуры площадки». Но даже этого будет недостаточно, потому что нужна сама площадка – здание со всеми коммуникациями.
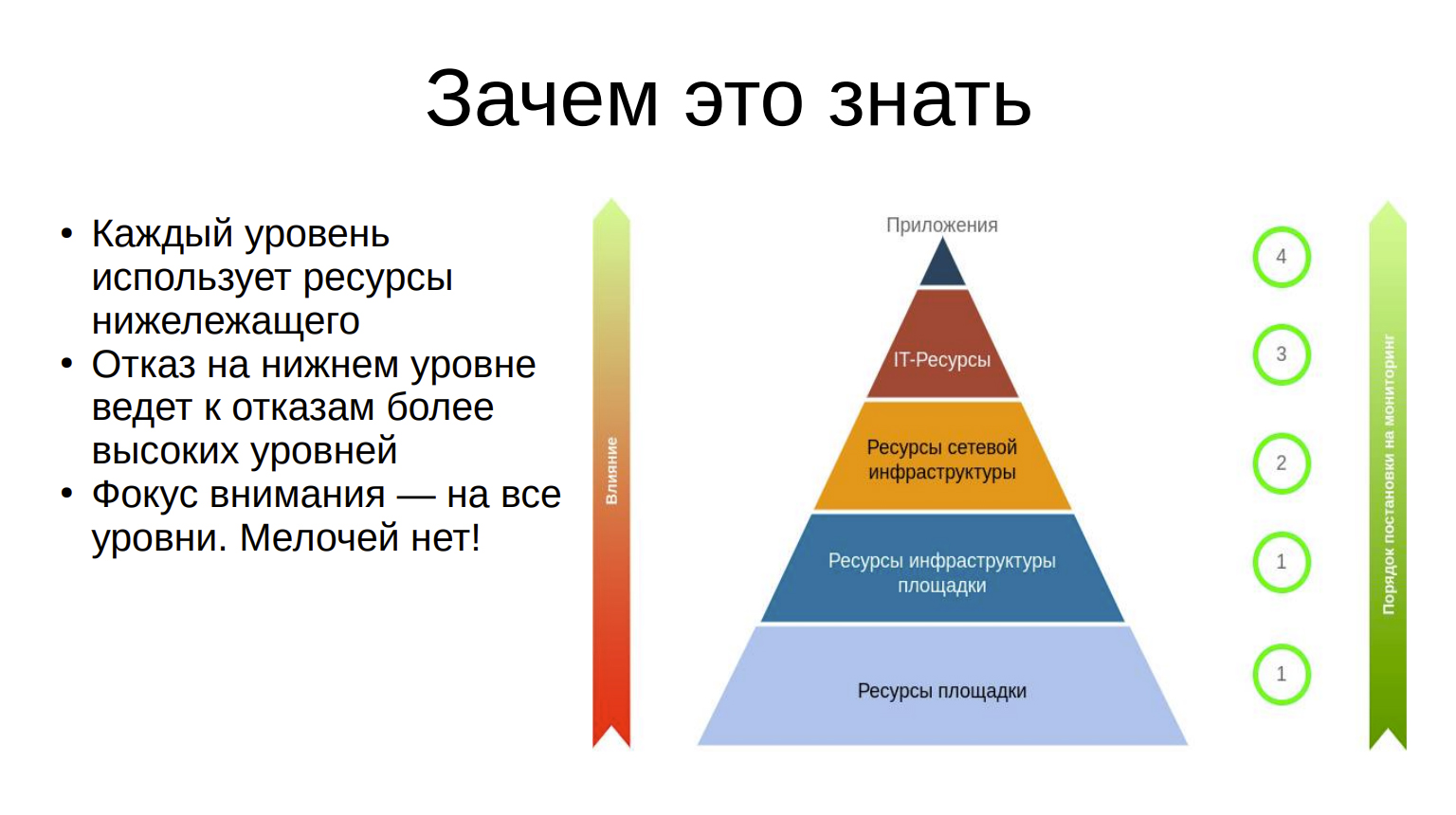
Таким образом, каждый нижележащий слой предоставляет сервисы для слоя вышележащего. Следовательно, чем ниже уровень в пирамиде, тем больше его влияние на работу всего ЦОДа. Поэтому нужно искать влияния на выручку и затраты на каждом из этих уровней, начиная снизу.
Зачем это знать?
На слайде вы видите иллюстрацию того, о чём я говорил. Мелочей, к сожалению или к счастью, нет, обо всём нужно помнить и знать.
Как искать. Алгоритм построения мониторинга.
Как можно строить мониторинг, зная два предыдущих вывода?
- Что может подвести в технике
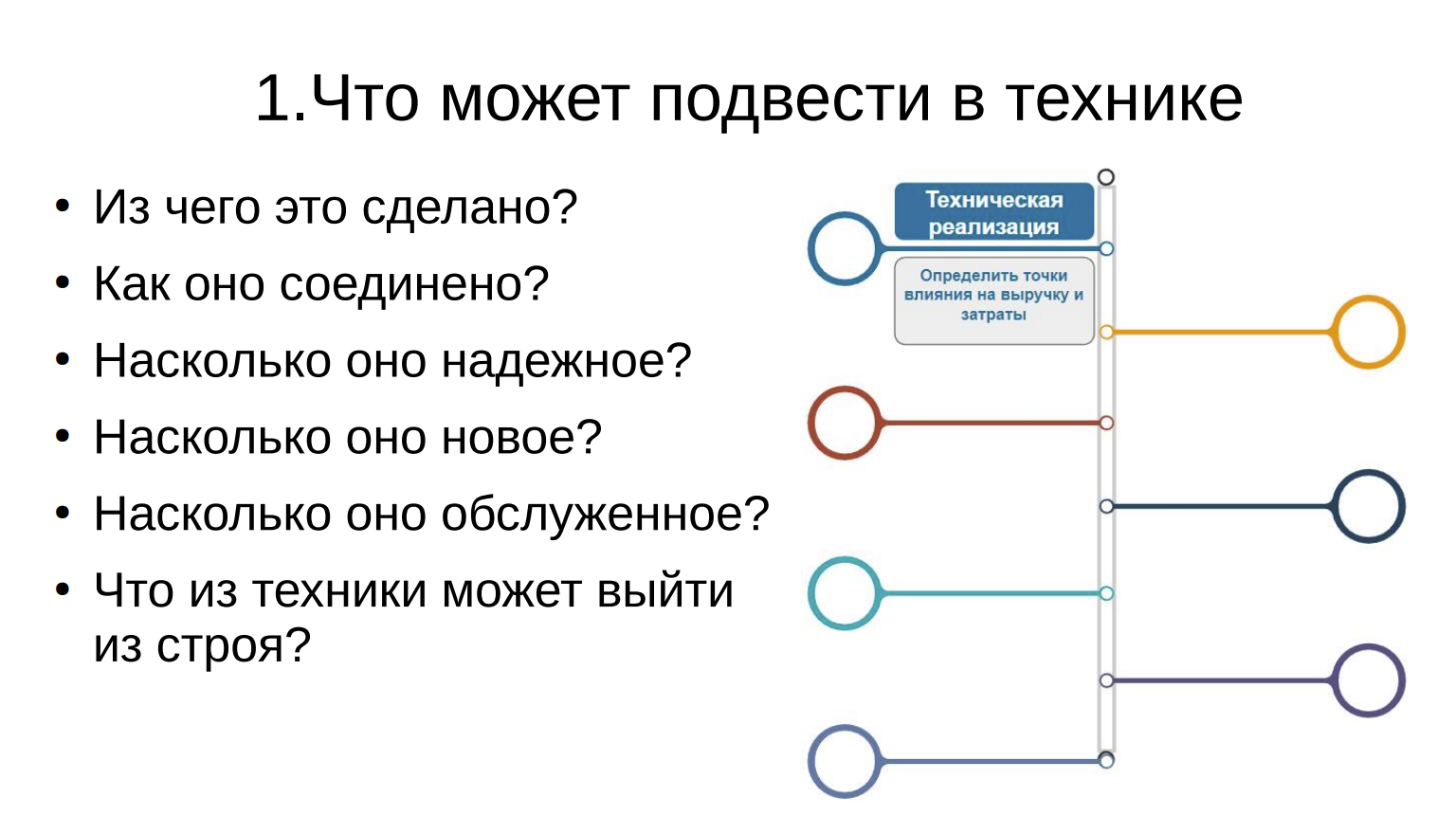
Когда мы получаем систему (либо мы ее проектируем со старта, либо мы ее получаем уже в эксплуатации), первое, что нужно сделать – осмотреться и понять из чего она сделана: из какого оборудования, как оно между собой соединено, как это сделано технически, архитектурно и физически. Насколько надежно оборудование, какая у него репутация на рынке, какой у него возраст и условия технической поддержки. Насколько надежны способы прокладки кабелей и насколько это все новое. Также нужно учитывать обслуживание и частоту обслуживания оборудования. Кондиционер обслуживающийся раз в квартал и кондиционер обслуживающийся раз в год – это две разные машины, они по-разному себя ведут. Это особенно важно в нехороших ситуациях.
Главное — зафиксировать, что из этого может выйти из строя и при каких обстоятельствах. При этом, когда мы задаем себе эти вопросы я призываю не стесняться и подходить к этому делу с, может быть, параноидальными нотками. Потому что, казалось бы, прокладка кабелей – что тут может случиться? Люди на экскаваторах нам не подконтрольны, они могут начать копать в любом месте и будет неприятно, если они порвут оба ввода, неважно, электрических или оптических.
Хорошей практикой является: иметь в ЦОДе не один кабель, а несколько, и заводить их разной географией. Таким образом, мы страхуемся от непредвиденных ситуаций.
Могу сказать, что в прошлой практике таких опытов было много и у нас была специальная программа по ЦОДам, где мы выявляли, как проложена оптика и энергетика, и разносили их по разным траншеям, если они находились в одной.
Необходимо обратить внимание на так называемые плоские кольца, когда оптическое кольцо собирает между собой несколько объектов, но при этом это кольцо лежит в одном кабеле. Да, оно работает, но если повреждается кабель, то перестаёт работать сразу всё.
Мы разобрались с системой, выявили и зафиксировали, какие технические компоненты могут выйти из строя. Это первый шаг.
- Что может подвести помимо техники
Второй шаг — посмотреть, что, помимо техники, может подвести. Здесь есть много факторов, влияющих на технику. Задаем себе вопрос, кто или что может это отключить. Например, человек может случайно отключить что-то. В моей практике был случай, когда щиток был удачно расположен, и люди, работавшие в ЦОДе, случайно отключили ряд автоматов своими движениями. Поэтому мы начали ставить козырьки на автоматы.
Еще одним фактором, который может отключить, является вода. Это частое явление, особенно когда ЦОД находится в арендованном помещении, где есть риск протечек. Поэтому мы фиксируем, кто или что может все отключить или сломать. Примеры таких случаев включают пронос техники, которая задевает коммуникации, или существующие стойки, или монтажника, который может случайно уронить распределительный шкаф.
Мы внимательно смотрим на всю систему, фиксируем возможные точки уязвимости и оцениваем вероятность таких событий.
- Как выглядит, когда подвело
Следующий важный вопрос, когда мы поняли, что у нас может сломаться технически или под влиянием человеческого фактора, как понять, что что-то случилось, не находясь на объекте, и какие будут последствия.
Мы наблюдаем температуру, потребление, трафик и другие показатели, которые могут указывать на проблемы. Но как определить, почувствовать тот момент, который мы зафиксировали как потенциально опасный? Как это может выглядеть во времени?
Некоторые проблемы могут произойти взрывообразно – бах, и света нет. Всё понятно. А другие могут накапливаться постепенно, например, деградация оборудования. Деградация аккумуляторной батареи редко происходит сразу. Как правило, это процесс постепенный: растёт, растёт, растёт, а потом в один прекрасный момент – их не хватает, чтоб поддержать нагрузку.
Ещё один момент, можно ли это увидеть заранее? Деградацию оборудования можно увидеть заранее, уровень воды тоже.
- Как и чем это можно определить
Мы поняли, что растёт температура. Где она растёт? Как определить? Какими приборами измерять?
Прекрасно, когда в спроектированном автозале уже расставлены термометры. А если их нет, тогда что нужно добавить?
Более того, нужно понимать, какие значения параметров говорят нам о случившемся.
Контролируем напряжение, 220 – это хорошо. А 180? Это беда или не беда? А отсутствие одной фазы: плохо или хорошо?
Таких вопросов масса и нужно иметь на них ответ ещё на стадии проектирования.
- Что надо делать и кому
И вот мы поняли, что у нас нехорошо, случилась беда №17. Дальше нам нужно понять, что делать. Разные беды требуют разных реакций. Где-то надо бежать туда, а где-то наоборот оттуда. Где-то надо гасить, а где-то наоборот не гасить. Что надо делать? Есть ли в компании регламент на этот случай? Есть ли подразделения, которые ответственные за это? Кто должен этим заниматься? Есть ли ресурсы на это?
Важно также понять, что можно поручить роботу, особенно в больших хозяйствах, где объем таких событий большой. Многие из них имеют стандартизированные реакции, которые можно автоматизировать. Если мы знаем, что при определенной аварии нужно запустить скрипт, то нет необходимости вмешиваться вручную. Можно просто запустить робота, и он все сделает. Но это нужно понять и зафиксировать.
Еще один очень важный момент – на что могут повлиять эти действия и как это учесть. Здесь я привожу пример из нашей практики. Был пожар в ЦОДе, в котором мы занимали его часть. Слава богу, пожар полыхал в соседнем крыле, а не у нас. Как тушат пожары, я думаю, вы знаете теоретически. Очень просто – пожарные обесточивают здание и проливают его этаж вверх и этаж вниз, чтобы все было мокрое. Других технологий тушения пожара нету.
Ну вот теперь представьте вот такую вот технологию в ЦОДе: сначала обесточили, потом как следует полили. Что от него останется? Ничего. Вот какие шансы такой ЦОД поднять? Быстро — никаких. Мы понимаем, что если есть возможность пожара, то у нас должно быть железобетонный DRP(disaster recovery plan), которая позволит максимум все, что возможно, утащить с этого ЦОДа на другие площадки. На этих других площадках должны быть подготовленные ресурсы. А что мы не можем утащить, у нас должен быть какой-то человек в клиентской службе, который клиентам сообщит, что «уважаемый клиент, мы очень дико извиняемся, но ваш сервис временно недоступен. Мы сделаем все, чтобы его поднять в ближайшее время». Пожар — это вещь, которая действительно угрожает и с которой надо сильно считаться.
Это очень хороший пример того, как важно оценивать реакцию на какую-то аварию, ее влияние на другие сервисы.
- Что, кому и как сообщать
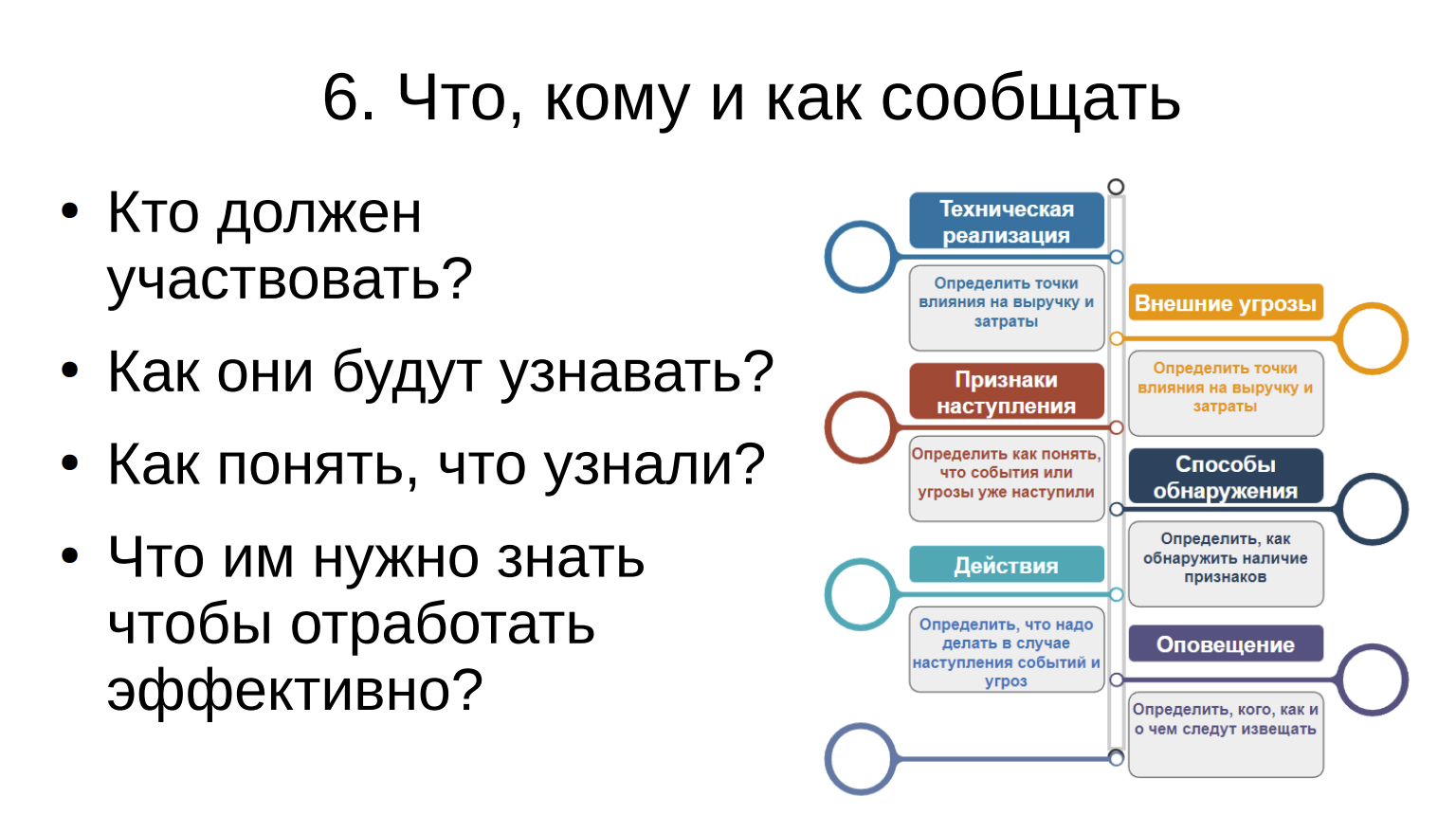
Хорошо, мы определили, что вот при такой беде нам нужно задействовать вот этих и вот этих. Есть люди, есть регламенты, есть ресурсы.
А как они будут узнавать, как эти люди вообще живут, по какому расписанию, где они находятся географически? Есть у них люди круглосуточные? Если нет, то надо им звонить, писать, слать какие-то короткие сообщения. Как понять, что они их получили и узнали? Вот отправили мы сообщения и думаем, что все происходит, а оно не происходит, потому что человек работает где-то внизу и потому что он выключил телефон, потому что там еще тысячи причин, и ничего не происходит. Как убедиться, что они узнали? Вот это тоже важный момент.
И очень важный момент, который я все время подчеркиваю, а что вообще людям нужно знать, чтобы побежать и устранить эту аварию. Может быть, им нужно знать адрес, может быть, им нужно знать схему прохода. Это я подтягиваю из сотового прошлого, потому что базовые станции разбросаны по городу, они все индивидуальные, и это очень важный фактор – знать, как попасть на базовую станцию. Может быть, им нужно знать, что сломалось и какой ЗИП с собой взять. Может быть, им нужно знать, какие системы еще с этим делом взаимодействуют, для того, чтобы подключить еще каких-то смежников. Важно, дать человеку полный объем информации, необходимый ему для устранения.
Хорошая задача, при построении системы мониторинга — собрать всю информацию из разных систем и дать ему вводные данные.
- Реализуйте описанное в системе
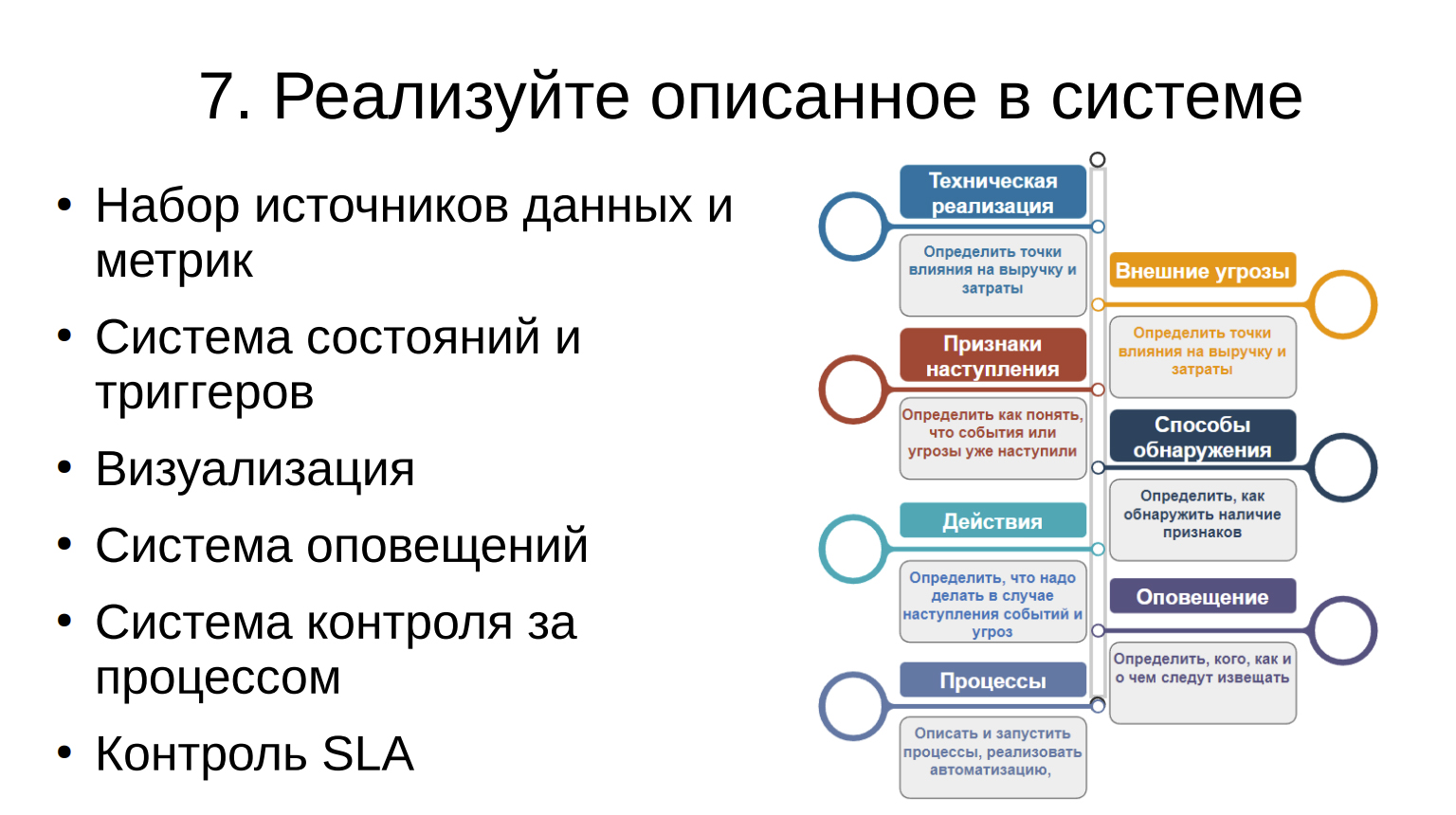
Вишенка на торте! Теперь, когда все это описали, возьмите и в системе мониторинга сделайте. Ну, это вещь очевидная, потому что, какой смысл все это дело описывать и расписывать, если потом не заниматься этим, но многие до этого не доходят.
Прежде чем начать заниматься системой мониторинга, нужно проработать ряд важных моментов, которые, к удивлению, занимают достаточно большой, неочевидный для людей, объем труда. Какие нам нужны данные, откуда они берутся, что это должно быть? Какие у них триггеры и как они срабатывают? Что такое хорошо, что такое плохо?
Вот тот самый пример, про который я говорил. Там 180-220. При каком изменении реагировать, как на него реагировать? Избегать дребезга или сразу реагировать?
У нас был случай в практике некоторое время назад, когда клиент попросил: «Вот у меня есть температура 25 градусов, если в автозале превышение 25 градусов, вы мне, пожалуйста, шлите уведомление в виде сообщения в телеграм». Мы ему стали слать, и у него так это все было замечательно устроено, что температура плавала ровно вокруг 25 градусов, и он получал в час порядка 30-40 штук этих уведомлений. Температура вроде как стала 25.1 — уже беда, надо слать. Потом она стала 25 или 24.9. Вроде уже не беда, мы ему шлем cancel. Эту вещь тоже надо продумать для того, чтобы это работало.
Визуализация. Как смотреть? Где хорошо, а где плохо? Можно смотреть в циферках, можно смотреть в картинках, можно посмотреть какой-то псевдографик — способов отображения массы.
Из опыта: мы делали системы мониторинга для удаленных контейнерных ЦОДов, в которых стандартного стационарного интернета нет. Они работают на какие-то предприятия, расположенные в тайге и шлют оповещения через СМСки. СМСки – это сим-карты. Сим-карта – это коммерческий тариф, как правило. На коммерческом тарифе кончаются деньги – СМСки отключают.
Через некоторое время приходит к нам заказчик и сообщает: СМСки перестали ходить. Что такое? Мы заглядываем — товарищ, у тебя деньги кончились! Хорошо, он положил деньги, но опять СМСки перестали ходить, товарищ у тебя опять деньги кончились. Он много денег положил, и вот они кончились чуть позже. Вот в итоге мы навернули еще один слой, который мониторит баланс и сообщает: смотри, у тебя деньги кончаются.
Это пример системы контроля за процессом: как понять не только то, что у тебя в следующий раз все получится, но и то, что процесс движется, что люди получили сообщения, что люди выехали на устранение, что люди приехали на устранение, что участвует вообще все, кто должен участвовать, что они что-то там делают, что работа идет в нужном направлении и так далее. Ну и SLA сверху, чтоб понимать, что люди действительно работают, а не дурака валяют. Такое, к сожалению, тоже случается, потому что все люди.
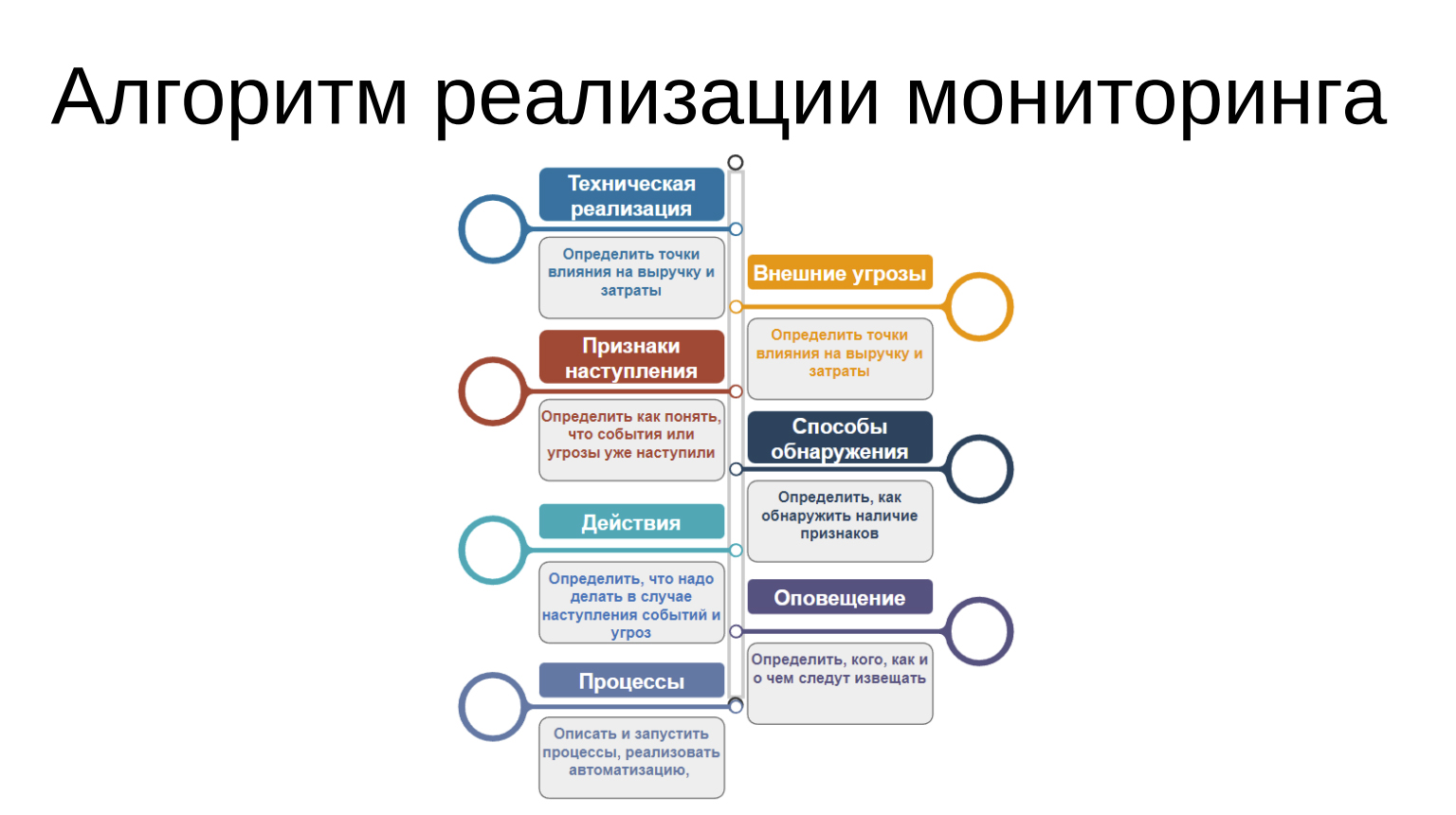
Алгоритм реализации мониторинга
Вот скелет, который образовался в ходе моего рассказа – является итогом. Посмотрели на техническую реализацию, зафиксировали внешние угрозы, определили способы обнаружения и признаки наступления, что с этим надо делать, кто в этом участвует и как из этого устроены процессы, как мы будем понимать, что они движутся, крутятся и все происходит. Смотрим на всё с точки зрения влияния на выручку и затраты. Это была теоретическая часть.
Теория без практики мертва, практика без теории слепа.
Теперь практическая часть на наглядных примерах.
Здравствуй паранойя
Здесь тот самый параноик, про которого я говорил. Недаром назвал слайд «Здравствуй, паранойя». Параноик – это человек, который всё подозревает, во всем видит беду и плохое. Вот здесь его надо привлекать по полной схеме, но слушать его аккуратно.
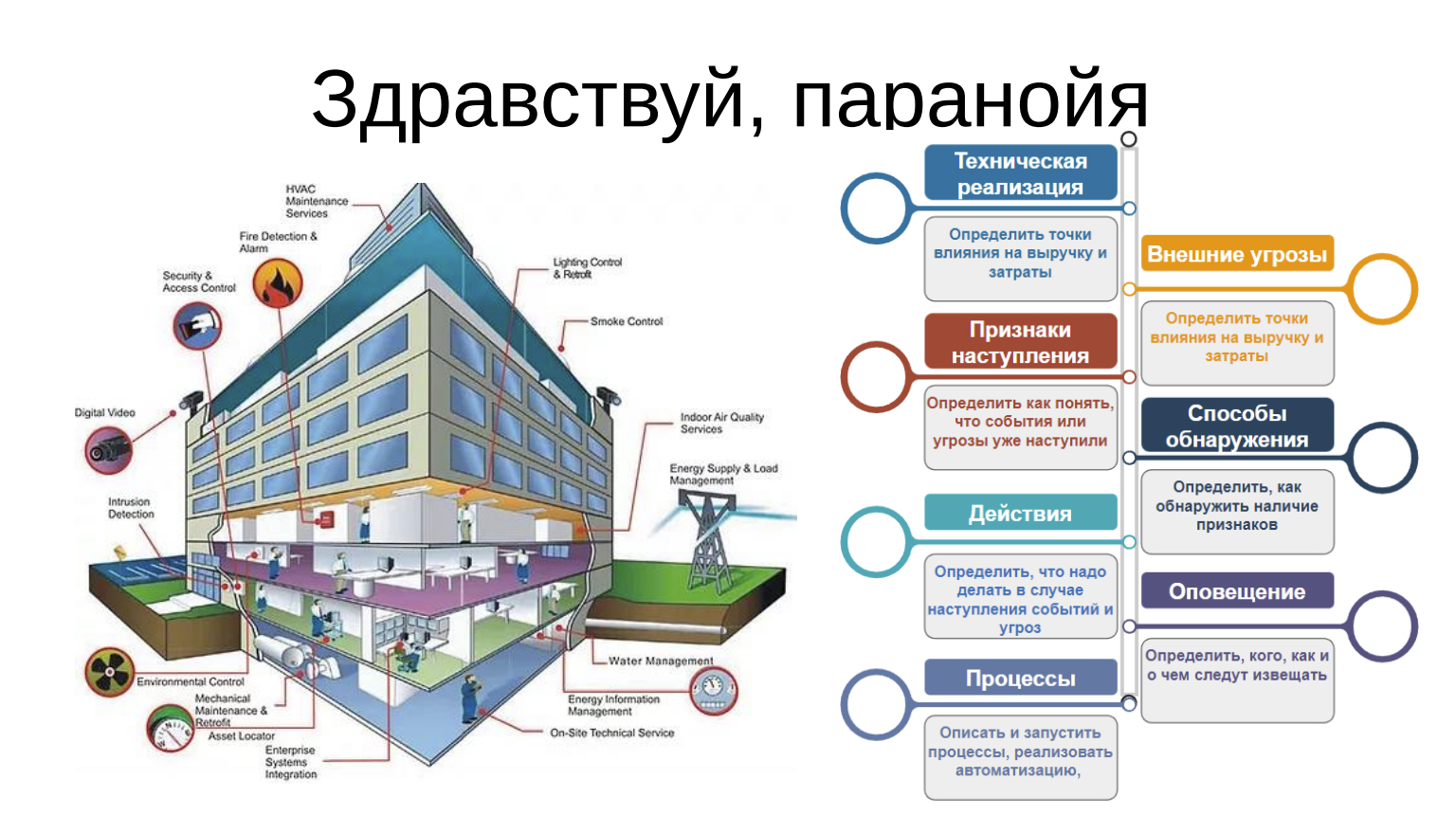
Техническая реализация + внешние угрозы
Предположим, есть у нас самый самый нижний уровень — площадка, на которой расположен ЦОД. Она состоит из собственного земельного участка, который, ну, для простоты, подозреваем, что принадлежит ЦОДу, хотя может быть и арендован, встречалось и такое. Есть подъездные пути, есть какое-то ресурсообеспечение: водопровод, энергетика, газопровод, водоотвод. И есть здание и соседи рядом.
Два первых пункта — техническая реализация и внешние угрозы. Что может угрожать участку? Может быть землетрясение, не берем, хотя, в принципе, возможно. Может угрожать затопление и может угрожать снег. Затопление, в моей практике было, как это не удивительно, у нас стандартно затапливало после дождей один из ЦОДов. В канализации с водоотведением были проблемы, вода стояла большая и вода шла вся в подвал здания. В подвале здания, на удачу, была расположена электроустановка. И также может быть снег. Для отдельных территорий снега может быть столько, что в ЦОД просто не попасть, это немного притянуто, но ситуации такие были.
Подъездные пути используются для того, чтобы в ЦОД приехали клиенты. Или чтобы в ЦОД что-то срочно привезли или увезли из него что-то нужное. Что с ним может случиться? Может случиться блок по погоде. Бывали случаи в моей практике, когда дороги просто перекрывали. Где-то их замело снегом, где-то их затапливало. Да и людям, которые отвечают за безопасность граждан, не важно, ЦОД у тебя там или не ЦОД — дорога закрыта и все.
Случается перекрытие дорог по организационным причинам. Живем в Санкт-Петербурге, прекрасно знаем, как время от времени перекрывают въезды на кольцевую, когда в Пулково кто-то важный садится или взлетает. По административным причинам попадались в моей практике такая экзотика, как частные дороги. Дорога, которая не общественная, не государственная, частная. И владелец этой дороги может ограничить по ней проезд или брать за это деньги. Как правило, это происходит так: все живут, все ездят, все пользуются, все хорошо. Потом приходит новый хозяин, понимает, что это вещь, с которой может получить денежку, а он не получает, ставит человека со шлагбаумом и начинаются разборки.
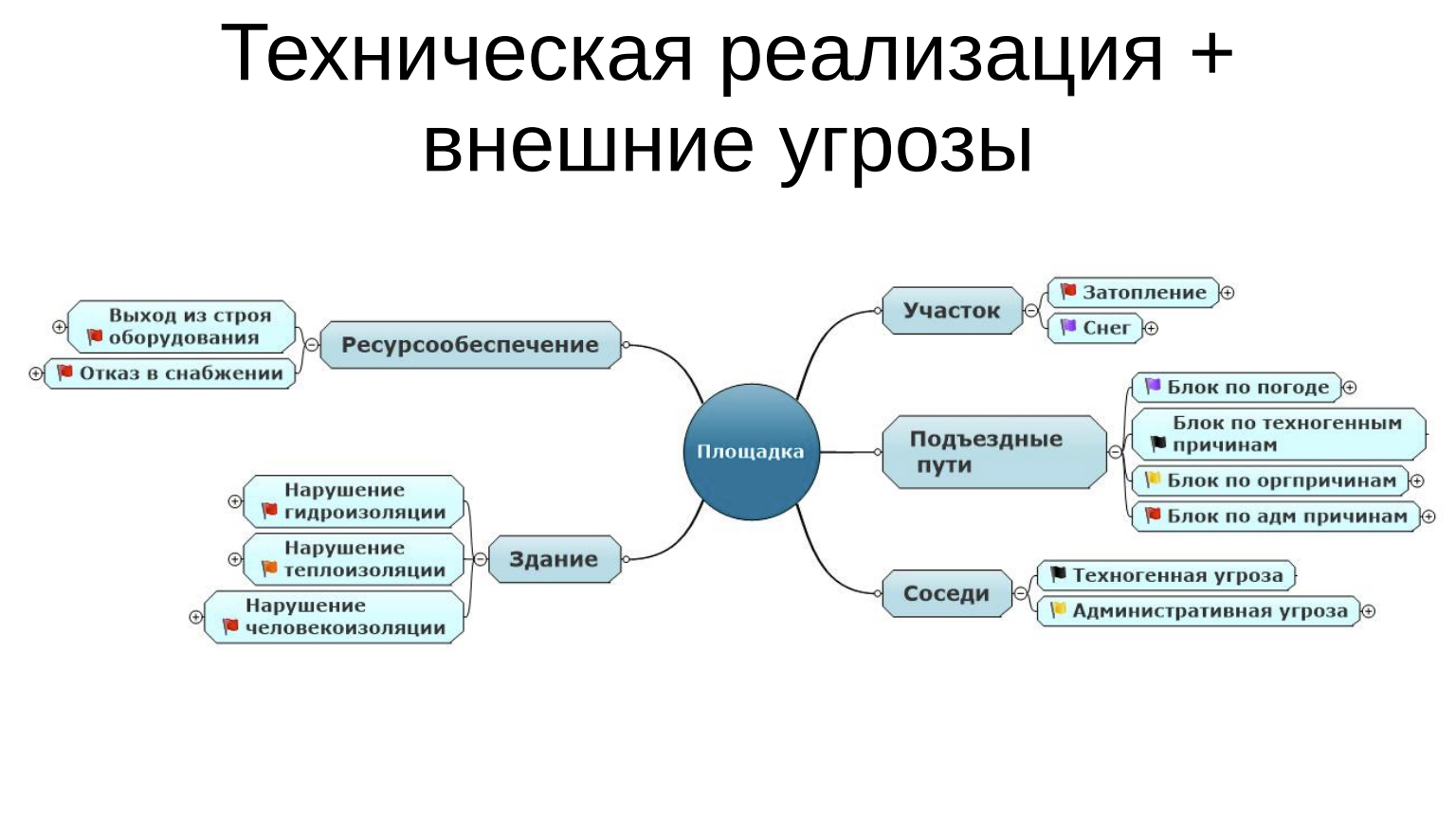
Соседи в контексте техногенной угрозы. Это соседи по типу автозаправочных станций, химических предприятий, которые могут взорваться или произвести утечку какую-нибудь.
Административная угроза. Это вещи, связанные с приездом первых лиц, когда перекрывают территорию вокруг каких-то участков, или с какими-то социальными проблемами. Краем сталкивались с устранением волнений в местах лишения свободы, когда перекрывали территорию, реально перекрывали доступ на участки.
Что может случиться со зданием? Может быть нарушение гидроизоляции — появляется вода там, где ее не должно быть. Нарушение теплоизоляции, начинает свистеть ветер. Нарушение человекоизоляции — я так назвал, то есть какие-то такие вещи, которые позволяют людям попадать в ЦОД там, где они не должны попадать.
Проблемы с ресурсообеспечением. Например, выход из строя оборудования: сломался насос, потекла труба, или что-нибудь там раскопали, и, как результат, отказ в снабжении. Смех смехом, но мы несколько раз нарывались на ситуации, когда потеряна и где-то в бухгалтерии не оплачена платежка за электричество, за воду, за домен неоплаченный, в конце концов. Это приводит к тому, что с утра приходишь, а ничего не работает. Почему? Потому что перекрыли. Почему? Потому что деньги не заплачены.
Это на уровне параноика рассмотрен только маленький кусочек нижнего уровня, который называется «ресурсы площадки».
Признаки наступления
Давайте посмотрим, что с этим можно делать. Я буду по нисходящей вырезать, чтобы просто показать и проиллюстрировать принцип, о котором я говорил.
Значит, затопление. Как можно понять, что у нас произошло затопление? Над дверным покрытием есть вода и ее достаточно много. Она не уходит. Понятно, что вода после дождя это нормально, да, и даже много воды после дождя, это бывает. Но когда она не уходит, это явное затопление. Снег — то же самое. Снег выпал, ладно, но когда его много, когда он долго лежит — это тоже достаточно тревожный фактор.
По погоде: вода, снег долго лежат. Значит, по организационным или по административным причинам, по каким-то причинам мы сталкиваемся с тем, что нас не пускают и не дают нам этим пользоваться. Да, административные угрозы — невозможность или существенные ограничения в использовании. Как определить? А вот так, мы видим, что нас не пускают, и понимаем, что произошел отказ, мы видим, что у нас воды много и не выйти, понимаем, что произошло затопление.
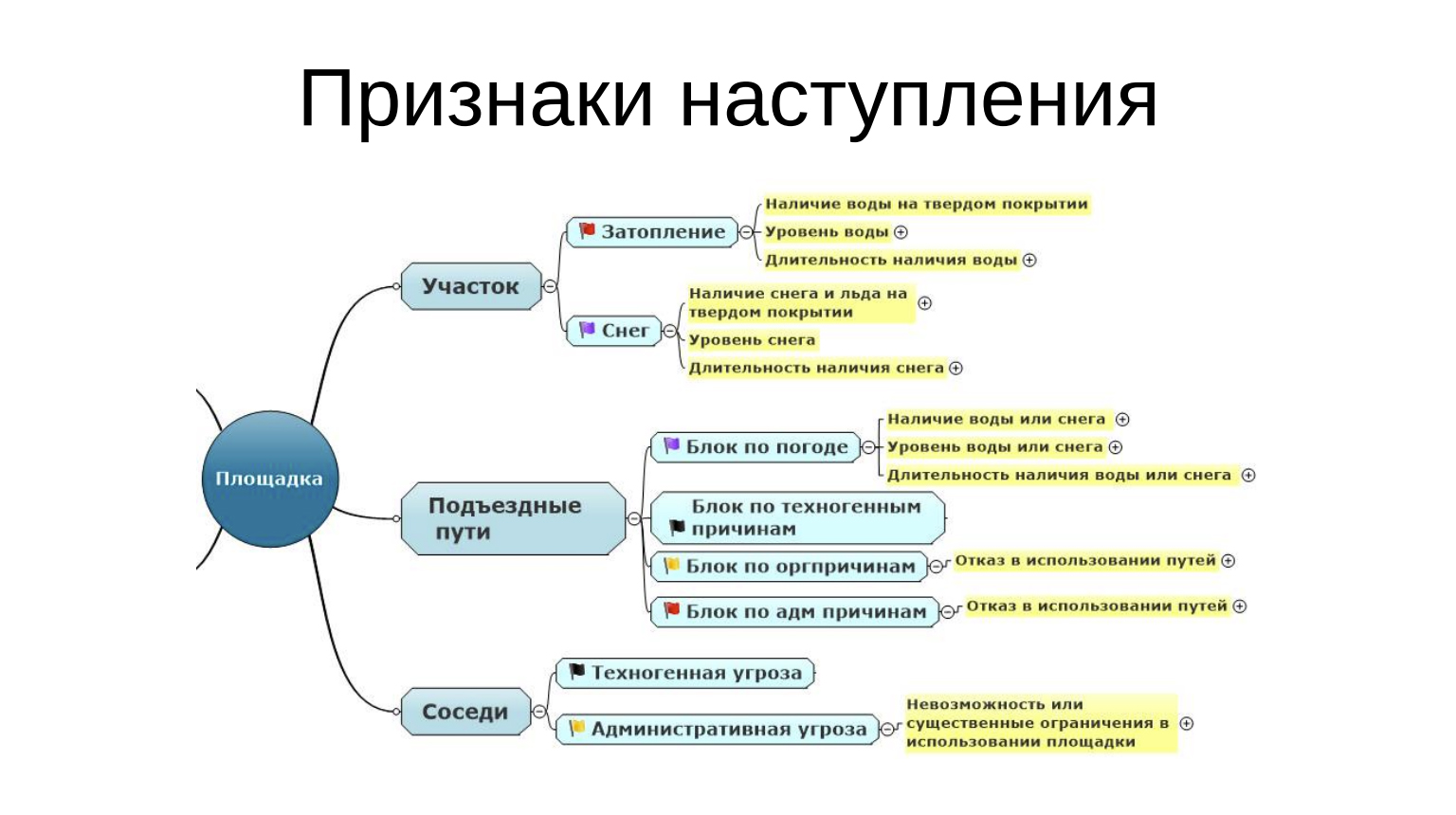
А как это дело обнаружить, особенно когда ты не находишься на площадке, а находишься вдалеке и сидишь в уютном кресле перед монитором? А обнаружить это можно следующим образом. Уровень воды: мы смотрим за системой водоотведения и смотрим за ее обслуживанием. Видим, что у нас система водоотведения есть, она обслужена, деньги по договору уплачены, крайний раз люди приезжали ей заниматься в прошлом году, и это нормально.
По погоде мы смотрим, что происходит с погодой. Мы смотрим, есть ли у нас договора с теми, кто снег убирать должен и заплатили ли мы по этим договорам. Здесь такой не очень очевидный инженеру “spin-off” в хозяйственную деятельность.
Это ответвление есть на всех уровнях, не только на площадке, потому что такого очень много. Я специально этот пример привел, потому что контроль бюджета и контроль договоров он есть практически везде. Везде, где кто-то что-то делает для нас, везде это должно быть предметом мониторинга, что в нужный момент для нас это сделают безо всяких проблем.
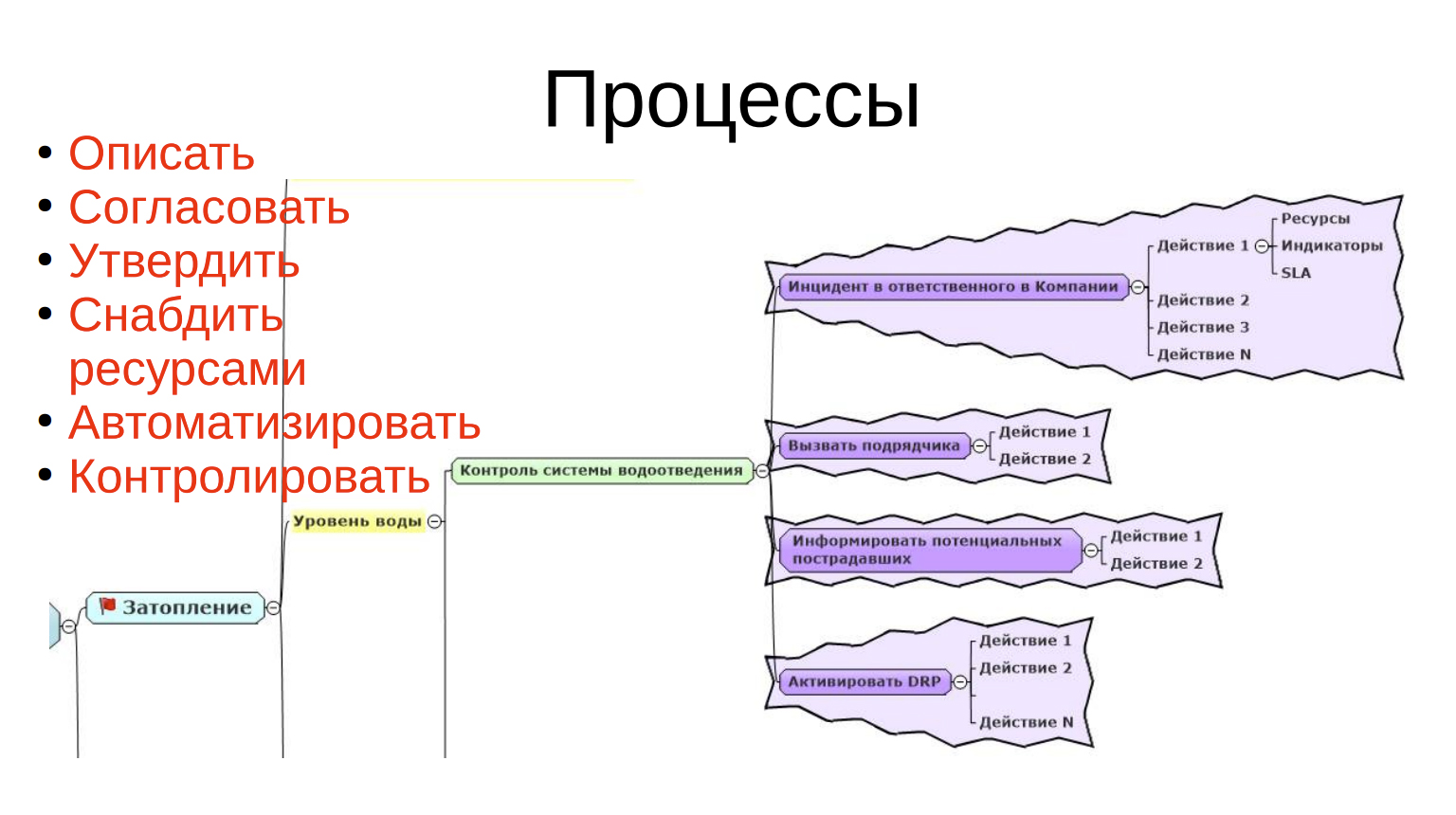
Действия
Вот мы поняли, что у нас большой уровень воды. Мы поняли, что у нас какие-то проблемы с водоотведением. Дальше что надо сделать? Надо знать, кто у нас ответственный в компании за работу в таких ситуациях и поставить, например, на него инцидент, вызвать какого-то подрядчика, который этим делом занимается, проинформировать потенциальных пострадавших. Мы понимаем, что завтра к нам должны приехать клиенты, может быть, имеет смысл позвонить и сказать: «Уважаемый товарищ, надевайте сапоги повыше». Ну, я шучу, конечно, что-то в таком ключе.
Контроль обслуживания: запросить ответственного в компании и эскалировать на руководство. Сказать еще: «Товарищи, дорогие, смотрите, уважаемое руководство, знайте, что у нас сейчас затопление по причине, вот как раз административной». И контролировать ситуацию, может быть, где-то пора активировать DRP.
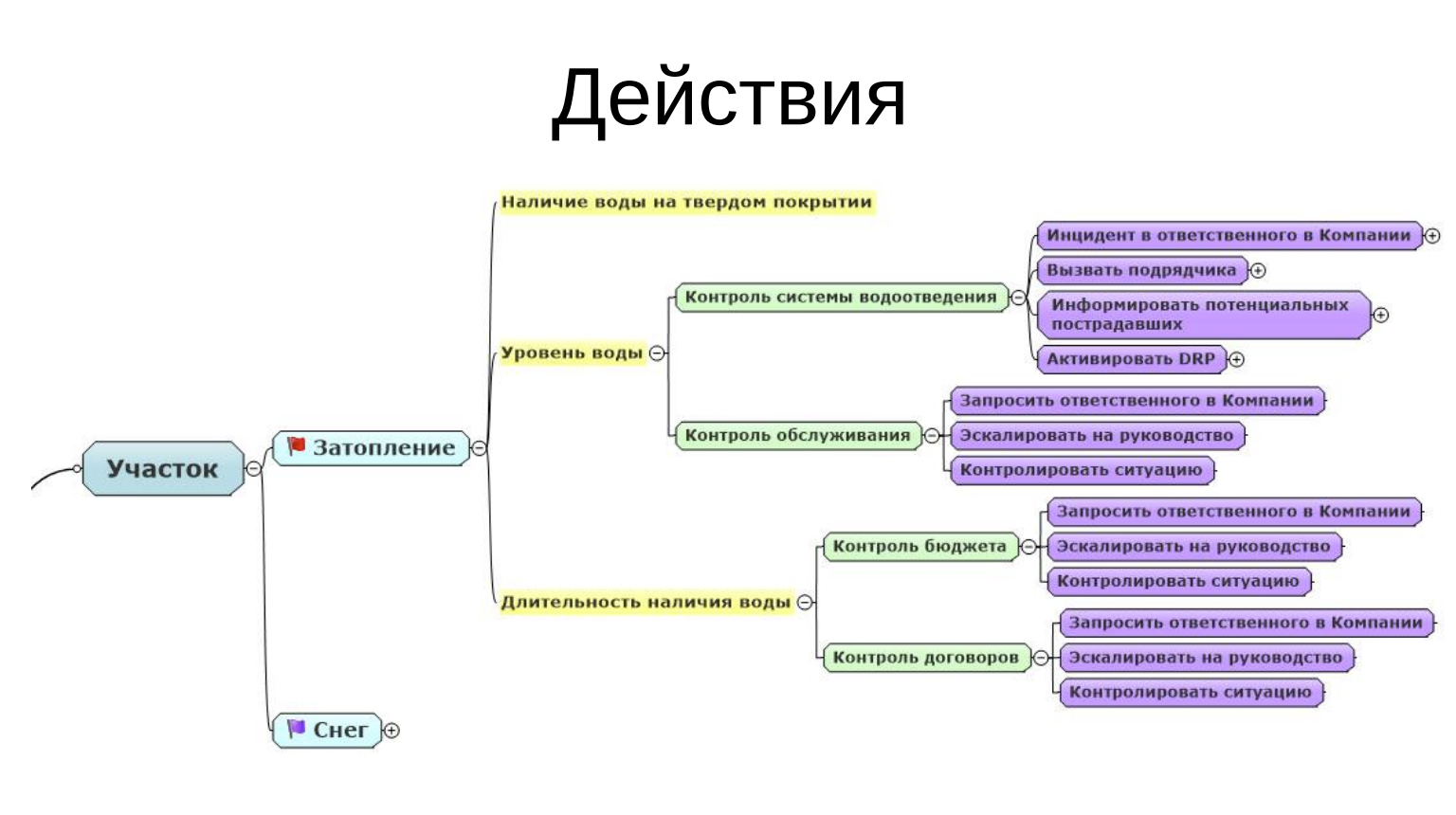
Это действия по каждой из ситуаций, которые нам нужно продумать, прописать.
Оповещения
Дальше я иду по алгоритму, как об этом оповещать. Мы разделяем сообщения на два типа: срочные и несрочные. Каждый из типов делится ещё на два: «основа для действия» и «информационные».
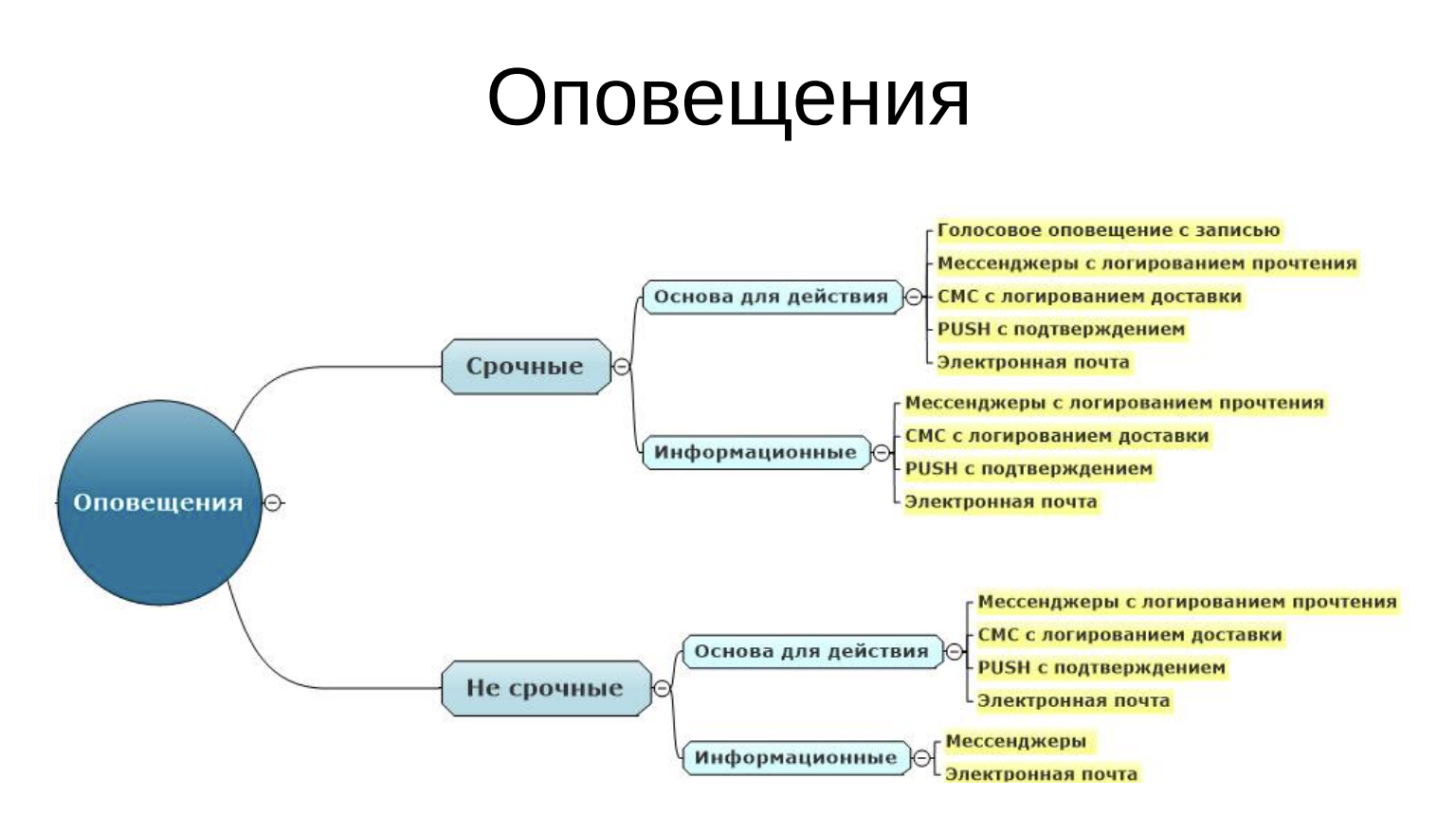
Дальше нужно выбрать, каким образом слать инцидент ответственным по компании: можно голосом — позвонить и сказать: «Уважаемый Иван Иванович, у нас затопление, идите выгоняйте воду». Может, послать ему СМСку, может быть, на электронную почту ему написать. Нужно для каждого из вариантов выбрать, как это делается и дальше сформировать из этого процессы. У нас есть инцидент ответственного, открывается Jira какая-нибудь или сервис-менеджер, заводится новый инцидент, вбивается в него необходимая информация и направляется куда-то туда. Соответственно, вот набор действий. В каждом действии видно: ресурсы, кто это делает, чем это делает, какие индикаторы используются, сколько времени у него это занимает; и так по каждому пункту.
Процессы
Это дело мы описали, согласовали и после сделали так, чтобы у Иван Ивановича был ресурс, чтобы он был на работе, чтобы у него был мобильный телефон или компьютер, в котором он сможет читать задачу в Jira. Это нужно, чтобы он понимал, что это входит его должностные обязанности.
Нужно автоматизировать все, что можно, и внимательно контролировать все, что происходит.
Три кита мониторинга
Это иллюстрация тех принципов, о которых я говорил, что есть у нас три кита: экономика, ресурсная модель и “скелетик-алгоритм”.
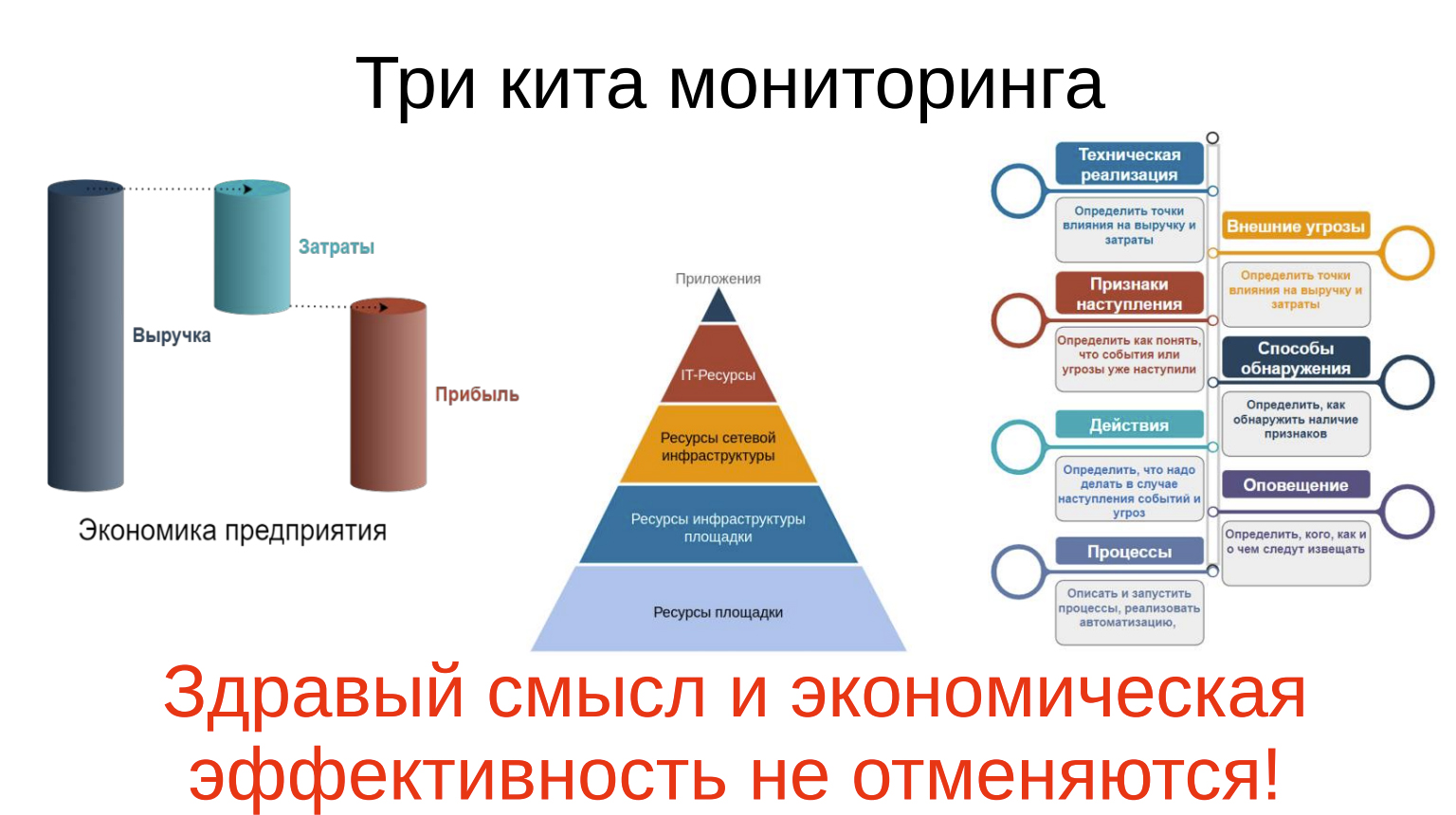
Помните, я говорил, что нужен параноик? Он действительно нужен, его надо слушать, но его не всегда надо слушаться, потому что здравый смысл и экономическая эффективность есть всегда. Как я говорю, защита от астероидов существует и вероятность того, что прямо вот ваш ЦОД попадет астероид тоже существует. Но это настолько дорого и настолько маловероятно, что этот риск, как правило, допускают и смиряются с ним. Мы смотрим на все, что приходит в голову параноику, или сами подходим с таким видением, но всегда фильтруем через здравый смысл и экономическую целесообразность.
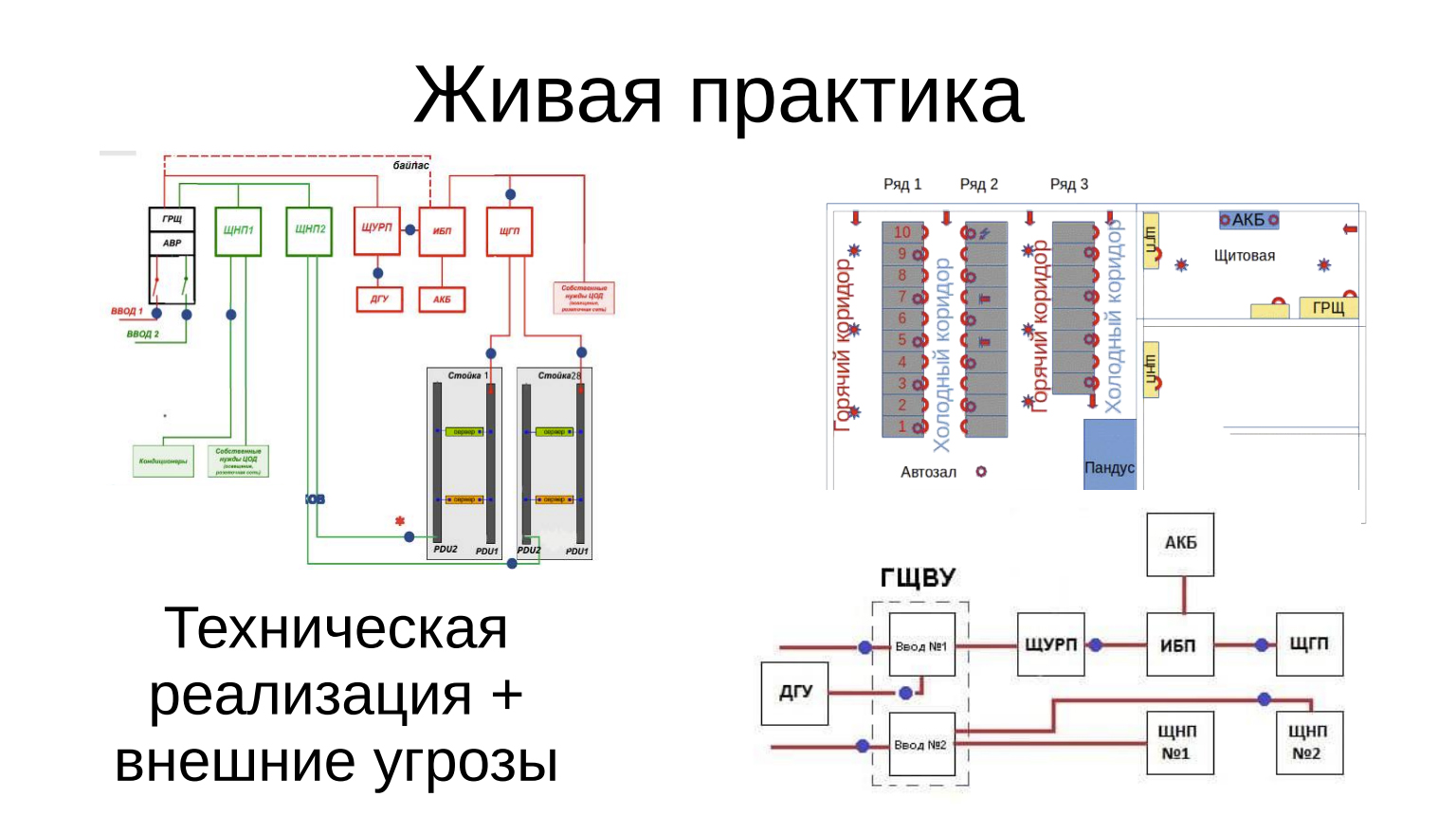
Живая практика
Здесь мы обычно демонстрируем одну из наших инсталляций. Мы с таким подходом подошли к нашим партнерам, не очень большому ЦОДу в Санкт-Петербурге. Строили для него мониторинг. Посмотрели техническую реализацию внешней угрозы, проанализировали, где ЦОД расположен, проанализировали, из чего сделан, проанализировали, что там может сломаться, что может угрожать функционированию ЦОДа, снабдили систему источниками информации, зафиксировали, как это должно выглядеть.
Оценили, что может сломаться, оценили, чем это определять и в каких точках: где какие датчики, где съемы, где температурные датчики, датчики протечки и так далее.
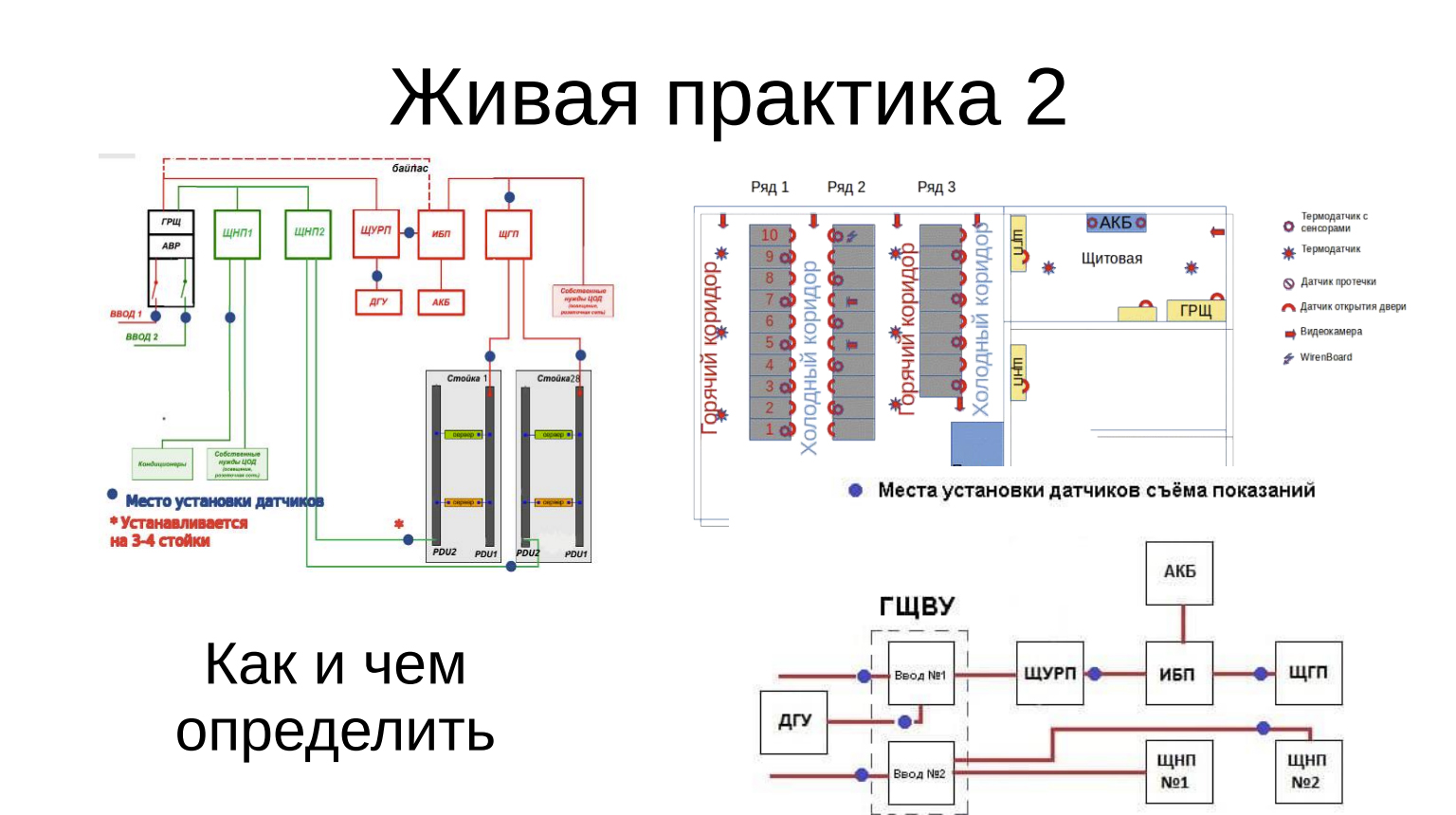
Определились, что делать, кого извещать. Этот набор сообщений и группы получателей, тексты — это все из реального проекта.
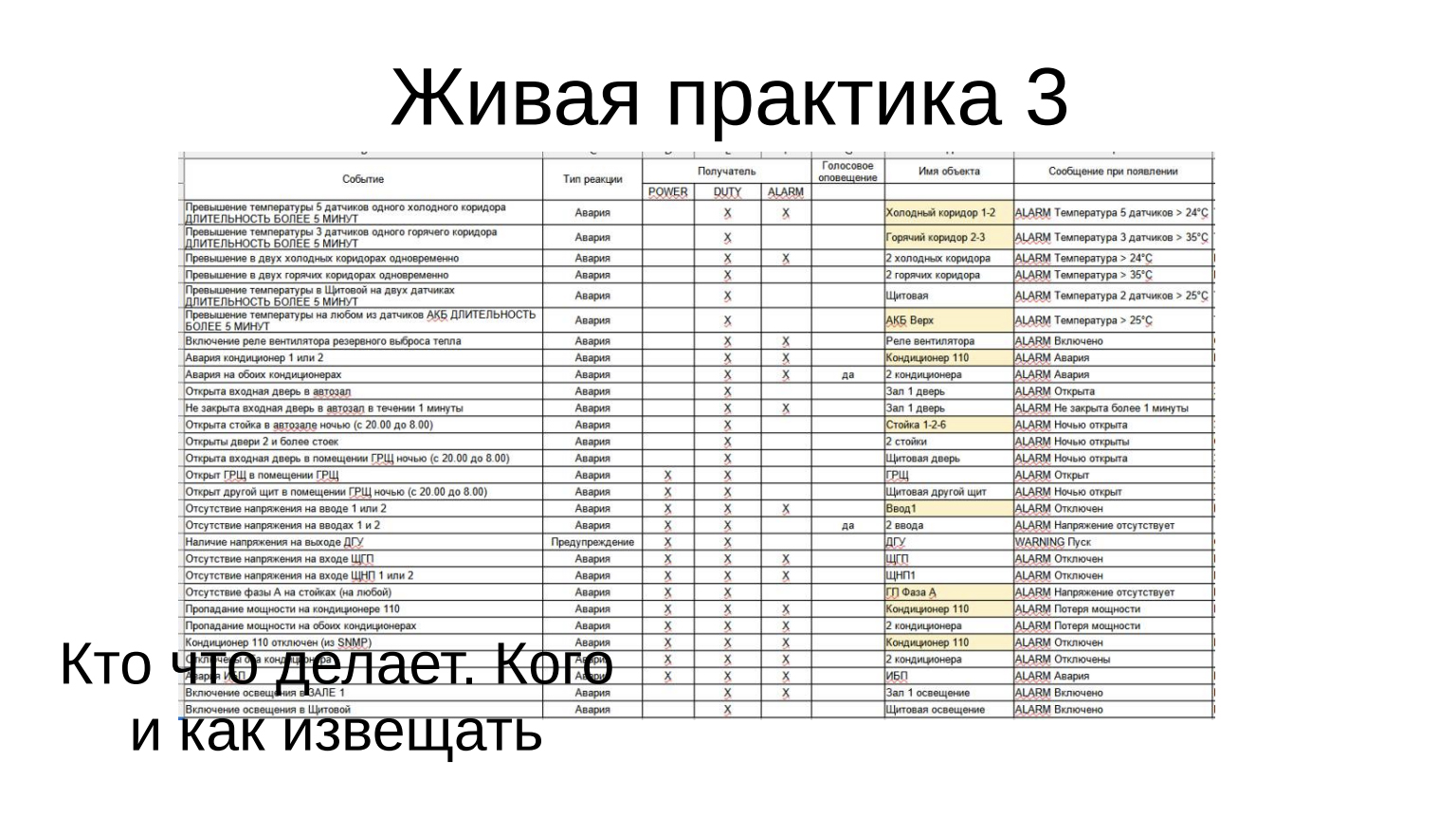
Процессы коллеги взяли на себя, и получилась такая система, которую мы демонстрируем.

Визуальные решения
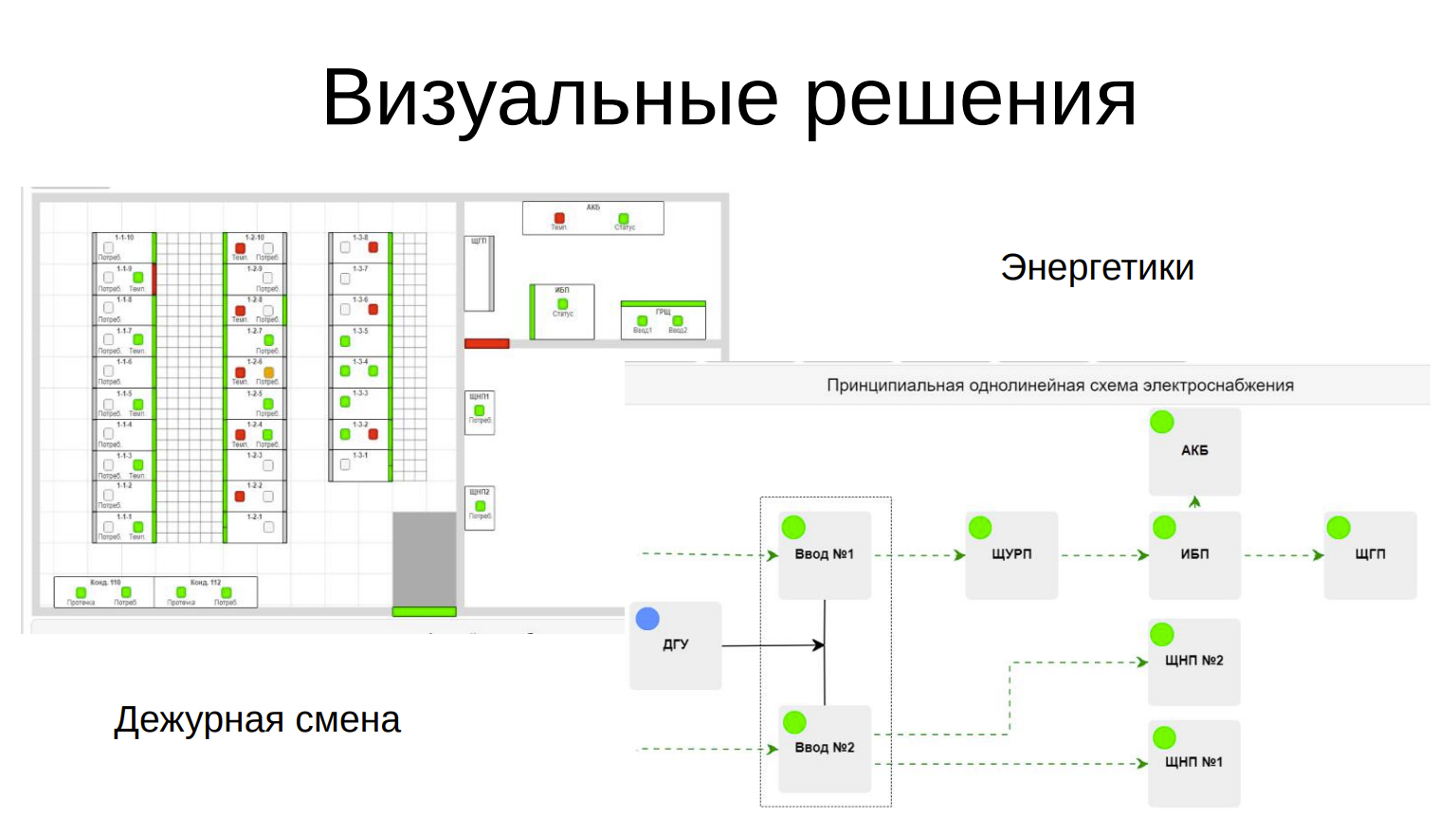
Мониторинг – это не только циферки и красные СМСки, можно решать графически, визуализировать, а можно совмещать не только мониторинг, но еще и эксплуатационные задачи. Различными визуальными решениями разграничивать данные для дежурной смены и для энергетиков.
Графика и символы
Есть возможность доставать информацию из оборудования и с помощью графики и символов наглядно показывать, что с ним сейчас происходит, чтобы не ковыряться в веб-интерфейсах и бегать по залу.

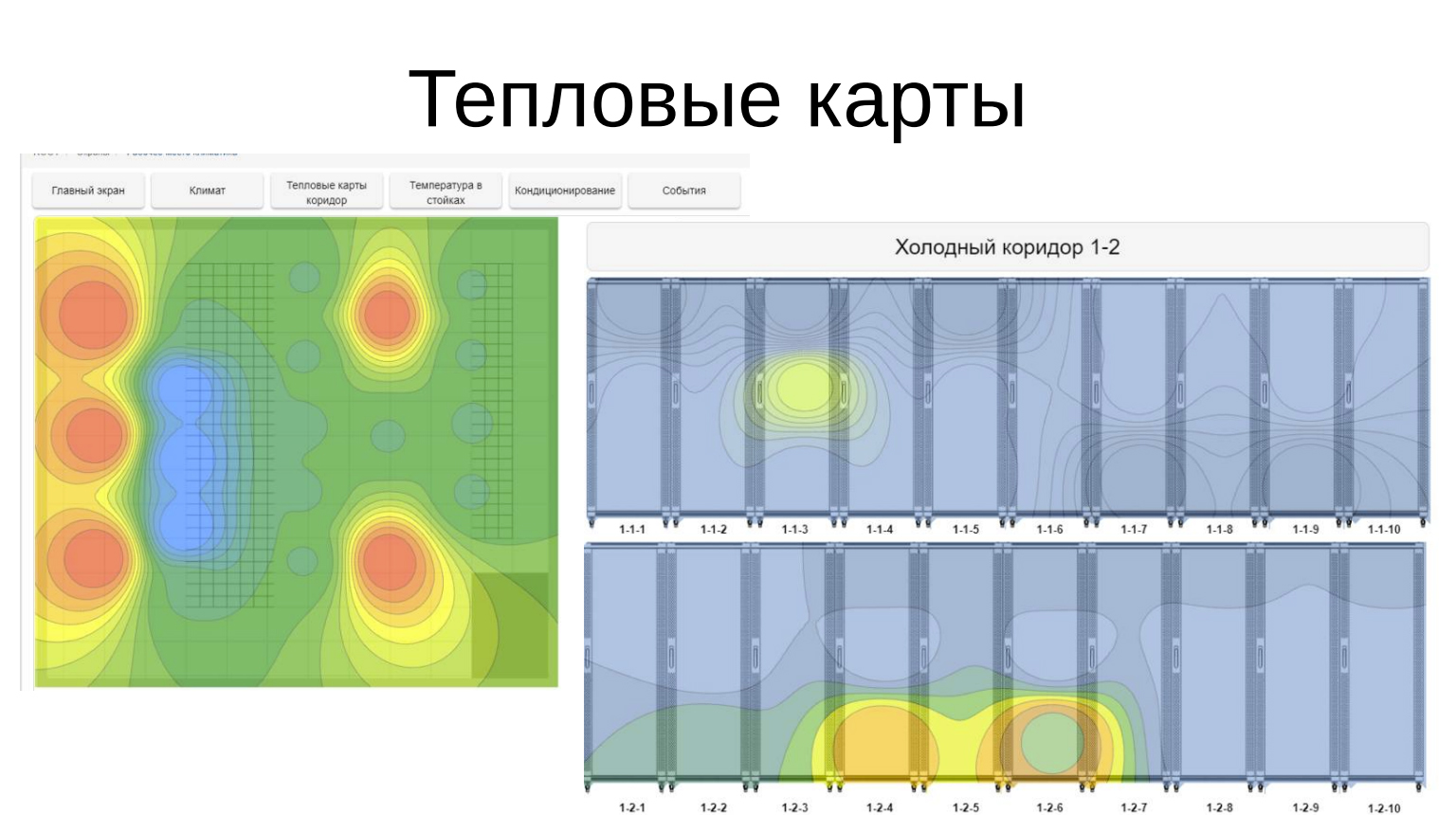
Тепловые карты
Есть возможность с помощью тепловых карт показывать, что происходит в ЦОДе. Это оказалось очень удобно, хотя коллеги сначала скептически к этому делу подходили, а потом, глядя на такую картинку, очень оперативно подкрутили кондиционеры, перенаправили воздушные потоки, потыкали затычки в стойке, заглушки, да и всю картину «испортили». Красных зон нет, теперь показывать нечего.
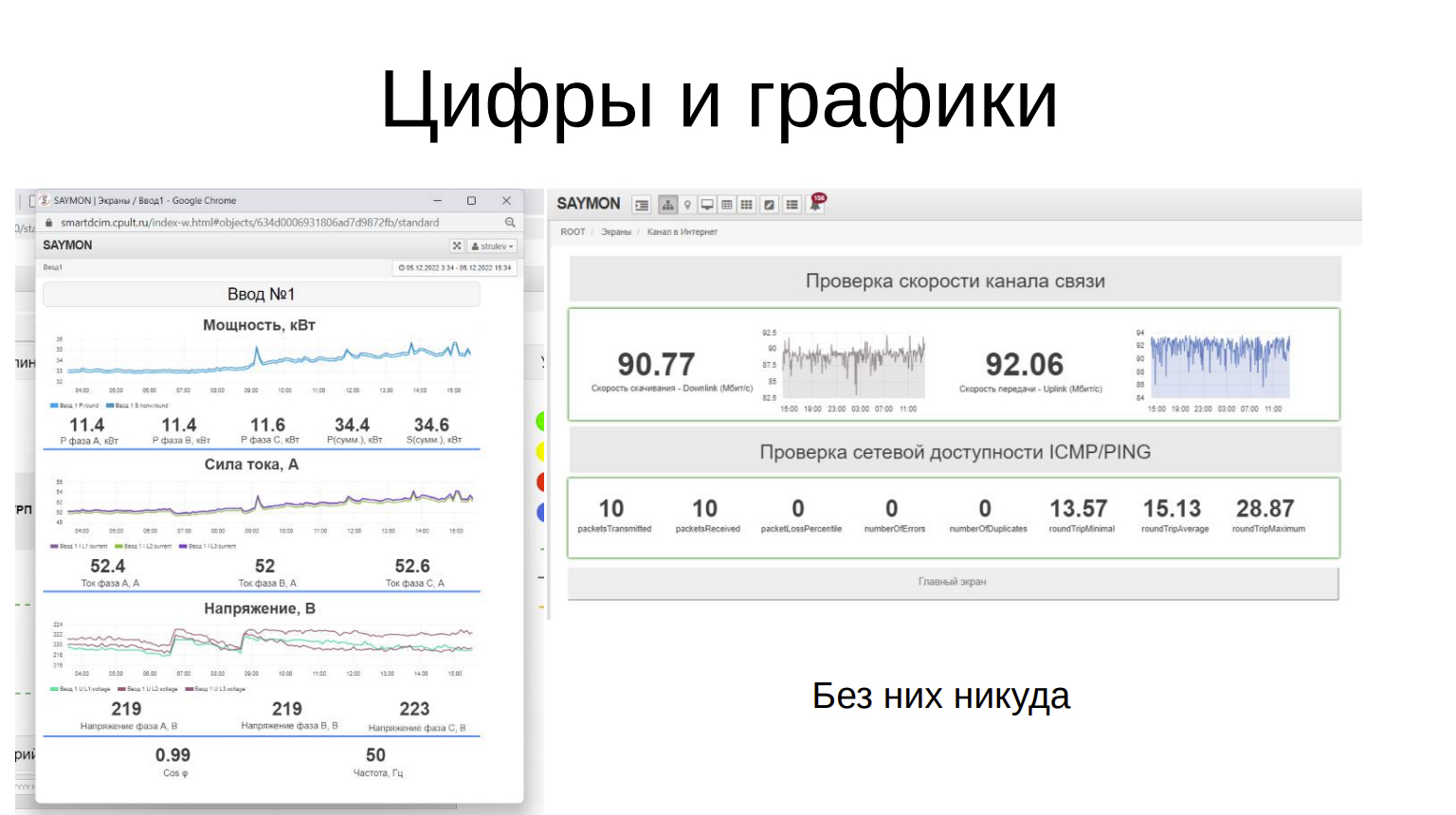
Цифры и графики
Цифры и графики тоже очень удобная вещь. Без них никуда.
И кино
И не то чтобы вишенка, но интересный функционал, который мы тоже в системе мониторинга показываем, это системы видео и фото фиксации. Мы интегрируемся с видео. Мы имеем возможность фотофиксации по триггеру. На слайде изображена фотофиксация по открытию двери.

Есть возможность подключения искусственного интеллекта к этому делу, те кейсы, которые у нас сейчас есть, например, с искусственным интеллектом, это FaceID. То есть человек узнается по фотографии. Также есть контроль изменения расположения предметов. Для чего это сделано? Это сделано для того, что когда какой-то подрядчик работает, или кто-то из собственных специалистов работает в зале, и он, например, расстилает упаковку, расстилает какое-то свое оборудование и не всегда за собой убирает, ну, просто потому что ему завтра приходить и продолжать работу, а делает он это, как правило, на решетках вентиляционных, и оборудование начинает перегреваться, если он там особенно много разложил. Чтобы не бегать и не принимать у каждого работу, была сделана такая опция, которая там до начала работ фиксирует пространство вечером. Фиксирует и понимает, кто там был и что он после себя оставил хорошее или нехорошее. Люди довольны: хорошая технология, хороший инструмент, методика. Она дала людям тот результат, который можно назвать успехом.
- Подробности https://saymon.info/, https://smartdcim.ru/
- Партнеры https://saymon.info/partners/
- Клиенты https://cpult.ru/klienty-i-partnyory
- Техническая информация https://wiki.saymon.info/
Докладчик Струлев Константин, руководитель департамента DCIM. konstantin.strulev@saymon.info; +7 921 949 0014 https://t.me/KonsStru